
OpenAI cambia il mondo in 26 minuti! La versione gratuita di GPT-4 è qui, l’interazione vocale video avanza rapidamente fino a diventare un film di fantascienza
Questa mattina presto, una conferenza stampa di 26 minuti cambierà ancora una volta notevolmente il settore dell’intelligenza artificiale e le nostre vite future, e renderà infelici anche innumerevoli startup di intelligenza artificiale.
Questo non è davvero un titolo, perché si tratta di una conferenza stampa di OpenAI.
Proprio ora, OpenAI ha rilasciato ufficialmente GPT-4o, dove la "o" sta per "omni" (che significa completo e onnipotente). Questo modello ha le capacità di testo, immagini, video e voce. Questo è anche il GPT-5 An versione incompiuta.
Inoltre, questo modello di livello GPT-4 sarà disponibile gratuitamente per tutti gli utenti e verrà implementato su ChatGPT Plus nelle prossime settimane.
Per prima cosa riassumiamo subito i punti salienti di questa conferenza. Si prega di leggere di seguito per un'analisi più funzionale.

Punti chiave della conferenza stampa
- Nuovo modello GPT-4o: apre qualsiasi input di testo, audio e immagine e può generarsi direttamente a vicenda senza conversione intermedia
- GPT-4o ha ridotto significativamente la latenza vocale e può rispondere all'input audio in 232 millisecondi, con una media di 320 millisecondi, che è simile ai tempi di risposta umani nelle conversazioni.
- GPT-4 è gratuito e aperto a tutti gli utenti
- API GPT-4o, 2 volte più veloce di GPT4-turbo e più economica del 50%.
- Splendida dimostrazione dell'assistente vocale in tempo reale: la conversazione è più simile a quella umana, può tradurre in tempo reale, riconoscere le espressioni e riconoscere lo schermo attraverso la fotocamera, scrivere codice e analizzare grafici
- Nuova interfaccia utente ChatGPT, più concisa
- Una nuova app desktop ChatGPT per macOS, con la versione Windows in arrivo entro la fine dell'anno
Queste caratteristiche sono state descritte da Altman come "una sensazione magica" già nella fase di riscaldamento. Poiché i modelli di intelligenza artificiale in tutto il mondo stanno "recuperando il ritardo con GPT-4", OpenAI deve estrarre alcune cose reali dal suo arsenale.
GPT-4o gratuito e disponibile è qui, ma non è il suo punto forte
Infatti, il giorno prima della conferenza stampa, abbiamo scoperto che OpenAI aveva tranquillamente cambiato la descrizione di GPT-4 da "modello più avanzato" ad "avanzato".
Questo per dare il benvenuto all'arrivo di GPT-4o. La potenza di GPT-4o è che può accettare qualsiasi combinazione di testo, audio e immagini come input e generare direttamente l'output multimediale di cui sopra.
Ciò significa che l’interazione uomo-computer sarà più vicina alla comunicazione naturale tra le persone.
GPT-4o può rispondere all'input audio in 232 millisecondi, con una media di 320 millisecondi, che è vicino al tempo di reazione di una conversazione umana. Precedentemente si utilizzava la modalità vocale per comunicare con ChatGPT, la latenza media era di 2,8 secondi (GPT-3.5) e 5,4 secondi (GPT-4).
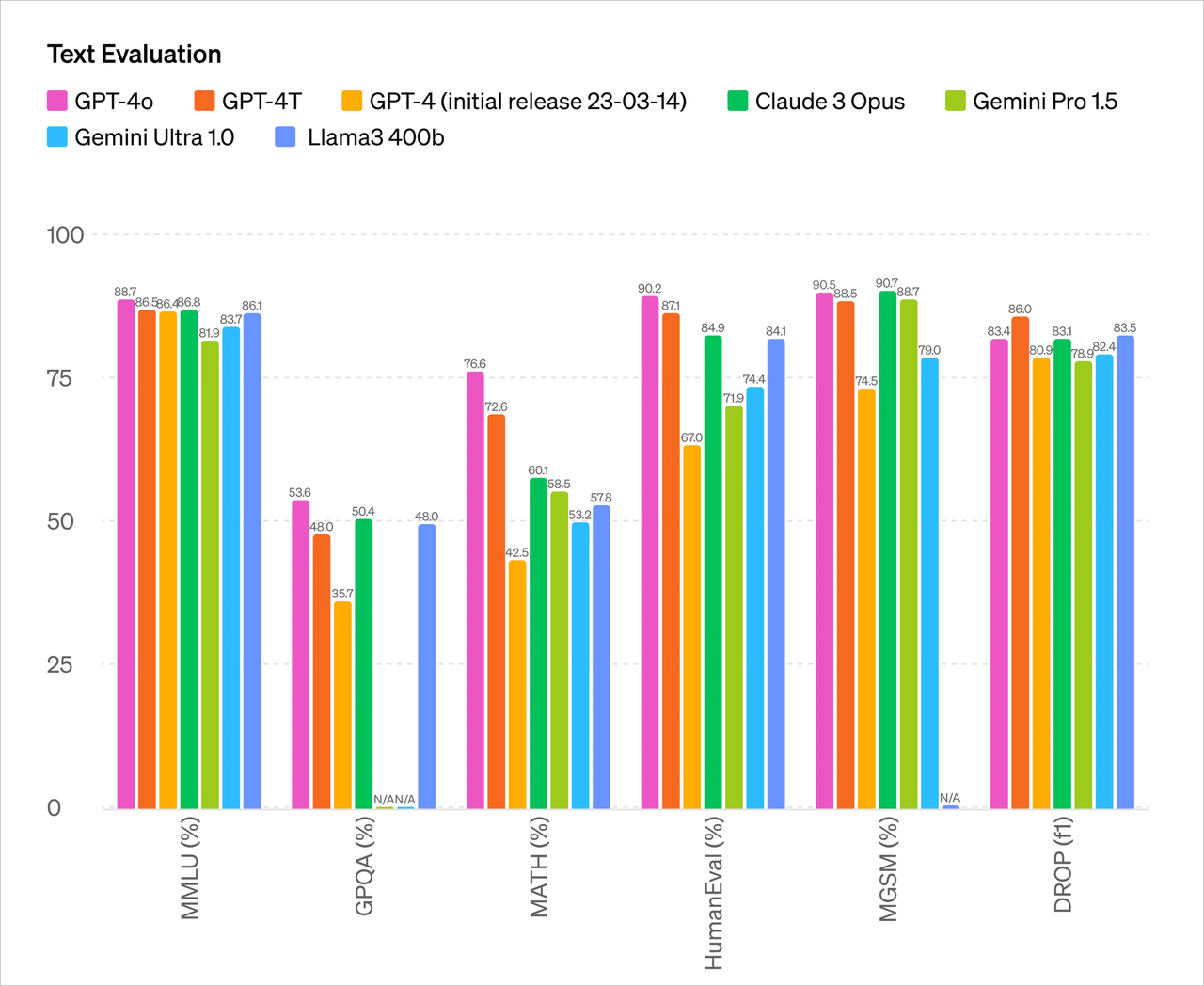
Corrisponde alle prestazioni di GPT-4 Turbo su testo in inglese e in codice, con miglioramenti significativi su testo in lingua diversa dall'inglese, pur essendo più veloce e più economico del 50% sull'API.

Rispetto ai modelli esistenti, GPT-4o offre prestazioni particolarmente buone nella comprensione visiva e audio.
- Puoi interrompere in qualsiasi momento durante una conversazione
- Può generare una varietà di toni in base alla scena, con stati d'animo ed emozioni simili a quelli umani
- Effettua direttamente una videochiamata con l'intelligenza artificiale e lascia che risponda a varie domande online
A giudicare dai parametri del test, le capacità principali di GPT-4o sono sostanzialmente allo stesso livello di GPT-4 Turbo, l'OpenAI più potente attualmente.
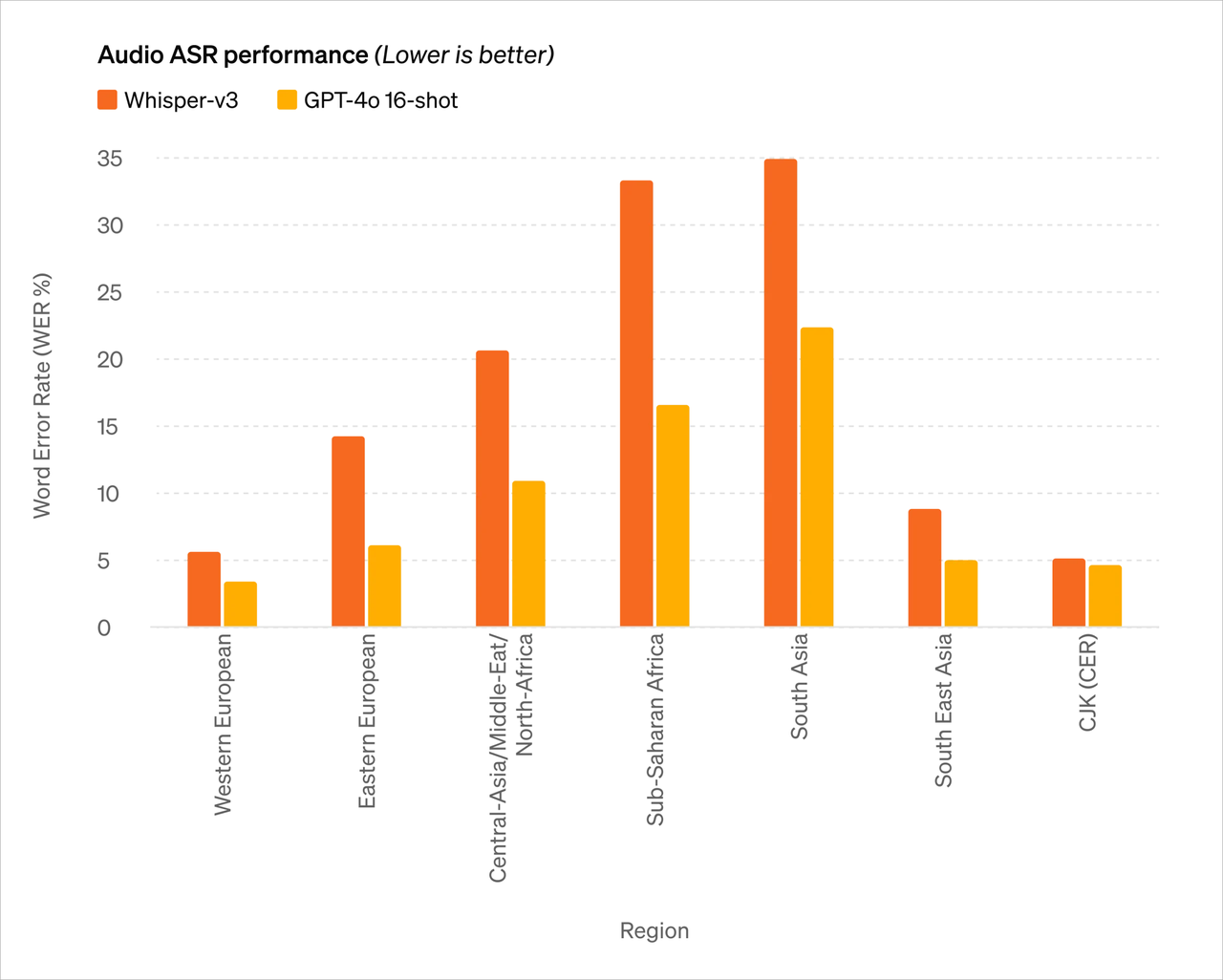

In passato la nostra esperienza con Siri o altri assistenti vocali non era ottimale. La conversazione con l'assistente vocale si svolgeva essenzialmente in tre fasi:
- Riconoscimento vocale o "ASR": audio -> testo, simile a Whisper;
- LLM pianifica cosa dire dopo: Testo 1 -> Testo 2;
- Sintesi vocale o “TTS”: Testo 2 -> Audio, pensa ElevenLabs o VALL-E.
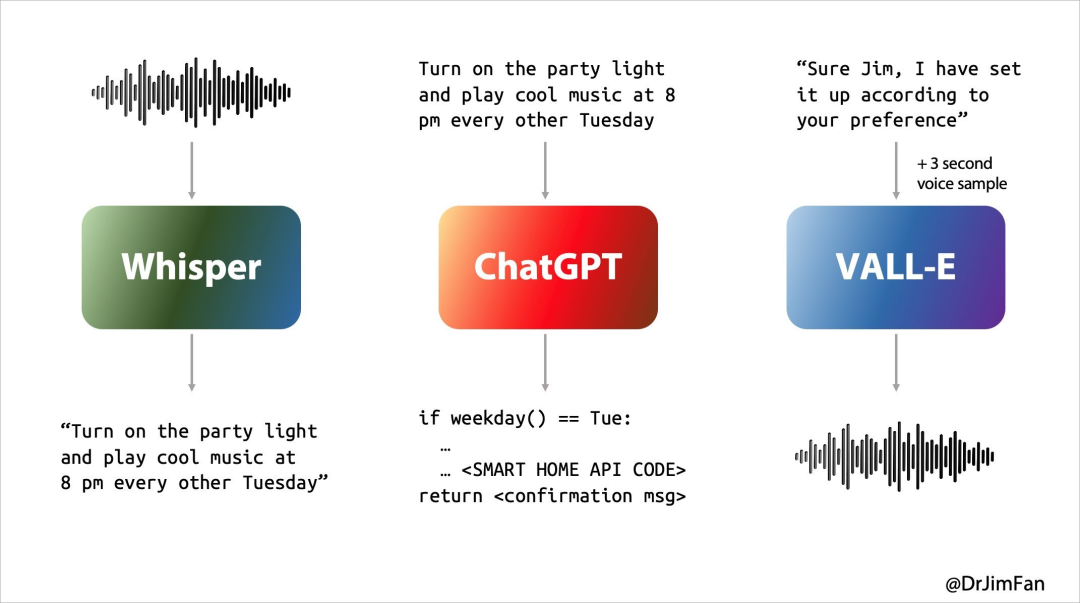
Tuttavia, le nostre conversazioni naturali quotidiane sono fondamentalmente così
- Pensa a cosa dire dopo mentre ascolti e parli;
- Inserisci “sì, um, um” al momento opportuno;
- Anticipare quando l'altra parte finirà di parlare e prendere immediatamente il comando;
- Decidere di interrompere la conversazione dell'altra persona in modo naturale e senza provocare risentimento;
- Pensa a cosa dire dopo mentre ascolti e parli;
- Inserisci “sì, um, um” al momento opportuno;
- Gestisci e interrompi con garbo.
I precedenti assistenti linguistici basati sull'intelligenza artificiale non erano in grado di gestire bene questi problemi e si verificava un notevole ritardo in ciascuna delle tre fasi della conversazione, il che si traduceva in un'esperienza deludente. Allo stesso tempo, molte informazioni vengono perse nel processo, come l’incapacità di osservare direttamente l’intonazione, più interlocutori o il rumore di fondo e l’incapacità di emettere risate, cantare o esprimere emozioni.

Quando l'audio può generare direttamente audio, immagini, testo e video, l'intera esperienza farà passi da gigante.
GPT-4o è un nuovissimo modello addestrato da OpenAI per questo scopo. La conversione diretta tra testo, video e audio richiede che tutti gli input e gli output siano elaborati dalla stessa rete neurale.
Ciò che è ancora più sorprendente è che gli utenti gratuiti di ChatGPT possono utilizzare GPT-4o per sperimentare le seguenti funzioni:
- Sperimenta l'intelligenza di livello GPT-4
- Ottieni risposte da modelli e reti
- Analizzare i dati e creare grafici
- Parliamo delle foto che hai scattato
- Carica un file per un abstract, una scrittura o un aiuto per l'analisi
- Utilizzo di GPT e GPT Store
- Crea esperienze più utili con Memory
E quando guardi le seguenti dimostrazioni di GPT-4o, le tue sensazioni potrebbero essere più complicate.
Versione ChatGPT "Jarvis", ce l'hanno tutti
ChatGPT non solo può parlare, ascoltare, ma anche guardare. Questa non è una novità, ma la "nuova versione" di ChatGPT mi ha comunque sorpreso.
compagno di dormite
Prendendo come esempio una scena di vita specifica, lascia che ChatGPT racconti una favola della buonanotte sui robot e sull'amore. Può raccontare una favola della buonanotte emozionante e drammatica senza pensarci troppo.
Può anche raccontare storie sotto forma di canto, che può fungere da compagno di sonno per gli utenti.
Maestro delle domande

Oppure, durante la conferenza stampa, lascia che ti dimostri come aiutarti a risolvere l'equazione lineare 3X+1=4. Può guidarti passo dopo passo e dare la risposta corretta.
Naturalmente, quanto sopra è ancora un po' un "gioco da ragazzi", e le difficoltà di codifica in loco sono il vero test. Tuttavia, il problema può essere facilmente risolto con tre colpi, cinque colpi e due colpi.
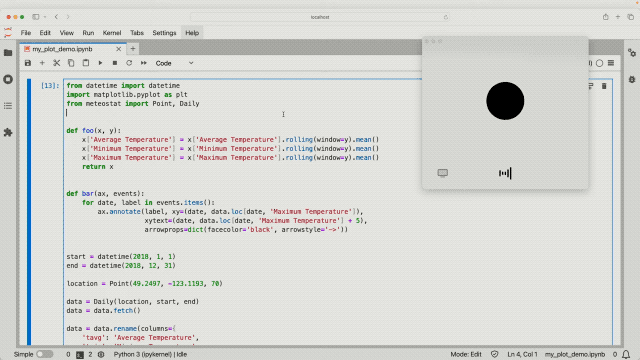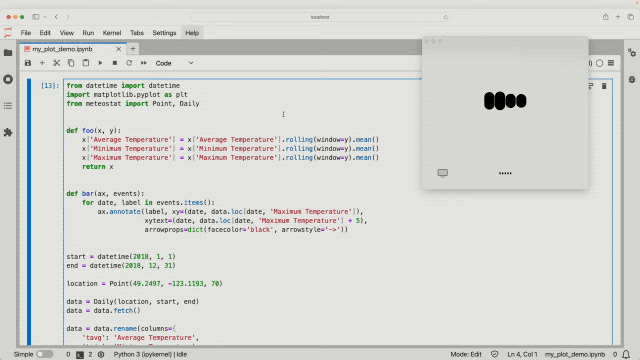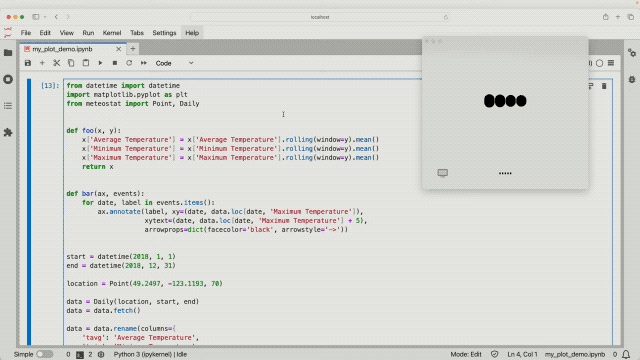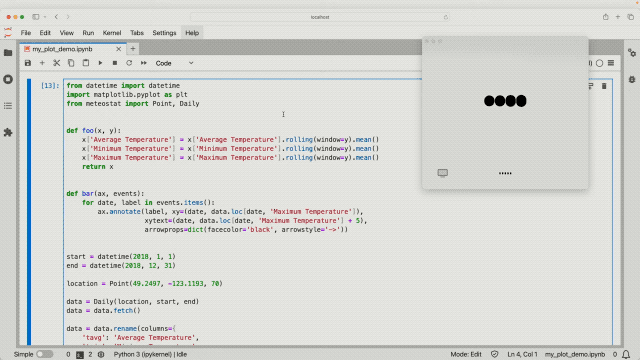
Con la "visione" di ChatGPT è possibile visualizzare tutto sullo schermo del computer, ad esempio interagire con il codice base e visualizzare i grafici generati dal codice. Eh, c'è qualcosa che non va? Allora la nostra privacy non sarà vista chiaramente in futuro?
traduzione in tempo reale
Il pubblico presente sulla scena ha anche posto alcune domande complicate a ChatGPT.
Traducendo dall'inglese all'italiano e dall'italiano all'inglese, non importa quanto usi questo assistente vocale AI, può farlo con facilità. Sembra che non sia necessario spendere molti soldi per acquistare un traduttore futuro, forse ChatGPT potrebbe essere migliore del tuo tempo reale. Il traduttore è abbastanza affidabile.
Al momento questo contenuto non può essere visualizzato al di fuori dei documenti Feishu.
▲ Traduzione in tempo reale (caso del sito web ufficiale)
Percepire l'emozione del linguaggio è solo il primo passo. ChatGPT può anche interpretare le emozioni facciali umane.

Durante la conferenza stampa, ChatGPT ha scambiato direttamente il volto catturato dalla telecamera per un tavolo, proprio quando tutti pensavano che stesse per ribaltarsi, si è scoperto che era perché la telecamera frontale accesa per prima era puntata sul tavolo. .
Tuttavia, alla fine, ha descritto accuratamente le emozioni sul viso nel selfie e ha identificato con precisione il sorriso "luminoso" sul viso.
È interessante notare che, al termine della conferenza stampa, il portavoce non ha dimenticato il "forte sostegno" di Cue da parte di Nvidia e del suo fondatore Lao Huang. He è davvero comprensivo della natura umana.
L'idea di un'interfaccia linguistica conversazionale era incredibilmente profetica.
Altman ha espresso in precedenti interviste che spera di sviluppare prima o poi un assistente AI simile a quello del film sull'intelligenza artificiale "Her", e l'assistente vocale rilasciato oggi da OpenAI sta effettivamente diventando realtà.

Brad Lightcap, direttore operativo di OpenAI, ha previsto non molto tempo fa che in futuro parleremo ai chatbot IA nello stesso modo in cui parliamo agli esseri umani, trattandoli come parte di una squadra.
Ora sembra che questo non solo abbia aperto la strada alla conferenza di oggi, ma anche una vivida nota a piè di pagina per le nostre vite nei prossimi dieci anni.
Apple ha lottato con gli assistenti vocali AI per tredici anni e non è riuscita a uscire dal labirinto, ma OpenAI ha trovato l'uscita da un giorno all'altro. È prevedibile che nel prossimo futuro "Jarvis" di Iron Man non sarà più una fantasia.
"Lei sta arrivando
Sebbene Sam Altman non sia apparso alla conferenza, ha pubblicato un blog dopo la conferenza e ha postato una parola su X: her.
Questa è ovviamente un'allusione al classico film di fantascienza "Her" con lo stesso nome. Questa è stata la prima immagine che mi è venuta in mente mentre guardavo la presentazione di questa conferenza.
Samantha nel film "Her" non è solo un prodotto, capisce anche gli umani meglio degli umani ed è più simile agli umani stessi. Puoi davvero dimenticare gradualmente che è un'intelligenza artificiale quando comunichi con lei.

Ciò significa che il modello di interazione uomo-computer potrebbe inaugurare un aggiornamento davvero rivoluzionario dopo l’interfaccia grafica, come ha affermato Sam Altman nel suo blog:
Le nuove modalità voce (e video) sono la migliore interfaccia per computer che abbia mai usato. Sembra un'intelligenza artificiale di un film e sono ancora un po' sorpreso che sia reale; Raggiungere tempi di risposta ed espressività a livello umano si rivela un grande cambiamento.
Il precedente ChatGPT ci ha permesso di vedere l'inizio dell'interfaccia utente naturale: la semplicità prima di tutto: la complessità è nemica dell'interfaccia utente naturale. Ogni interazione dovrebbe essere autoesplicativa e non richiedere alcun manuale di istruzioni.
Ma il GPT-4o rilasciato oggi è completamente diverso: non ha quasi alcun ritardo nella risposta, è intelligente, interessante e pratico. La nostra interazione con i computer non ha mai avuto un'interazione così naturale e fluida.
Qui si nascondono ancora enormi possibilità. Quando saranno supportate funzioni più personalizzate e la collaborazione con diversi dispositivi terminali, ciò significa che potremo utilizzare telefoni cellulari, computer, occhiali intelligenti e altri terminali informatici per fare molte cose che prima non erano possibili.
L'hardware AI non cercherà più di accumularsi. Ciò che è più interessante ora è che se Apple annuncerà ufficialmente la sua collaborazione con OpenAI al WWDC il mese prossimo, l'esperienza dell'iPhone potrebbe essere migliorata più di qualsiasi conferenza degli ultimi anni.
Jim Fan, scienziato senior del codice NVIDIA, ritiene che la cooperazione tra iOS 18, noto come il più grande aggiornamento della storia, e OpenAI possa avere tre livelli:
- Abbandonando Siri, OpenAI ha perfezionato un piccolo GPT-4o per iOS che funziona esclusivamente sul dispositivo, con la possibilità di pagare l'aggiornamento per utilizzare i servizi cloud.
- La funzionalità nativa alimenta i flussi della telecamera o dello schermo nel modello. Supporto a livello di chip per codec audio e video neurali.
- Integrazione con l'API operativa a livello di sistema iOS e l'API per la casa intelligente. Nessuno usa le scorciatoie di Siri, ma è tempo di rinascita. Questo potrebbe diventare un prodotto di agente AI con un miliardo di utenti subito pronto. È come un volano dati a grandezza naturale simile a Tesla per smartphone.
A questo proposito, mi dispiace per Google, che domani terrà una conferenza stampa.
Autore: Li Chaofan e Mo Chongyu
# Benvenuto per seguire l'account pubblico WeChat ufficiale di aifaner: aifaner (ID WeChat: ifanr) Ti verranno forniti contenuti più interessanti il prima possibile.
Ai Faner |. Link originale · Visualizza commenti · Sina Weibo
