
Il futuro di OpenAI potrebbe dover essere “salvato” da “Harry Potter”

La legge sul copyright è una spada affilata che pende sulle teste delle società di intelligenza artificiale.
Quando il New York Times ha annunciato ufficialmente la sua causa contro OpenAI e Microsoft per violazione, il filo dell’arma è stato nuovamente rivelato, il che sembrava indicare che il 2024 sarà un altro anno fondamentale.
Dopotutto, anche se il New York Times non ha proposto un importo specifico di risarcimento, ha richiesto alle due società di distruggere i chatbot e i dati di formazione coinvolti nell’utilizzo dei materiali relativi al New York Times.

È sempre stata una cosa “naturale” accumulare più dati per modelli di grandi dimensioni e addestrare un’IA più “intelligente”. Tuttavia, è ancora molto difficile “cancellare” dati specifici che sono stati integrati in calcoli di modelli di grandi dimensioni.
Esiste una buona analogia: cercare di "cancellare" dati specifici da un modello di grandi dimensioni è come cercare di rimuovere ingredienti come lo zucchero o il burro da una torta finita.
Se vincono la causa, i ricercatori non saranno in grado di escludere i dati del New York Times dai loro modelli esistenti, il che significa che dovranno distruggere l’intera torta.
Chi avrebbe mai pensato che Harry Potter avrebbe potuto aiutare i giganti dell’intelligenza artificiale a uscire dal loro stato passivo e persino partecipare allo sviluppo all’avanguardia della tecnologia dell’intelligenza artificiale su scala più ampia.

Non è facile "dimenticare tutto"
Dimentica! (Tutto è dimenticato)
Nel mondo di "Harry Potter", per proteggere il mondo magico, i maghi spesso lanciano incantesimi di amnesia sui Babbani per cancellare ricordi specifici dopo che sono entrati accidentalmente in contatto o sono stati testimoni di animali magici o oggetti magici.

Proprio come i maghi, anche i ricercatori sull'intelligenza artificiale stanno esplorando gli "incantesimi di oblio" che possono essere utilizzati su modelli di grandi dimensioni.
I ricercatori dell’Università di Washington, dell’Università della California, Berkeley e dell’Allen Institute for Artificial Intelligence hanno sviluppato un modello linguistico di grandi dimensioni chiamato “Silo” con l’obiettivo di creare un modello di grandi dimensioni in grado di rimuovere dati specifici per ridurre i rischi legali.
I ricercatori hanno diviso i dati di addestramento in due parti: dati a basso rischio di violazione e dati ad alto rischio.
Il team ha innanzitutto addestrato un modello utilizzando dati a basso rischio, come libri con copyright scaduti e documenti governativi.
Su questa base, quando il modello sta deducendo, può anche leggere una biblioteca contenente dati ad alto rischio, che contiene varie informazioni raccolte dalla rete e libri pubblicati. La libreria è flessibile, quindi i ricercatori possono aggiungere o rimuovere dati specifici dalla libreria in qualsiasi momento in caso di controversia sul copyright.
La ricerca mostra che le prestazioni del modello diminuiscono in modo significativo se addestrate solo su dati a basso rischio.
Per studiare ulteriormente l'impatto di testi specifici sul modello di grandi dimensioni, i ricercatori hanno utilizzato i romanzi di "Harry Potter" per addestrare e testare ulteriormente il modello.
Hanno creato due serie di dati: una serie comprendeva tutti i libri pubblicati tranne il primo "Harry Potter"; la seconda serie comprendeva tutti i libri pubblicati, esclusi 7 libri di "Harry Potter". Quindi utilizzare questi due set di dati per addestrare il modello.
Successivamente, hanno ripetuto il test, cambiando ogni volta i dati presentati dal primo gruppo al secondo, terzo e terzo romanzo di Harry Potter e così via.
Quando escludiamo i romanzi di Harry Potter dal set di dati, la perplessità del modello di grandi dimensioni diventa peggiore.
Ciò significa che se i romanzi di "Harry Potter" venissero eliminati, le prestazioni del modello grande peggiorerebbero.

▲Le conseguenze dell'eliminazione della Maledizione dell'Oblio
Sebbene il test di Silo aiuti i ricercatori a comprendere l’importanza dell’addestramento della qualità dei dati per le prestazioni di modelli di grandi dimensioni, questo approccio di “eliminazione” non significa “dimenticare” in senso stretto, ma più come “ridurre l’esposizione accessibile” di contenuti specifici”.
Nell'ottobre di quest'anno, i ricercatori Microsoft hanno provato un metodo più vicino al "dimenticare". Per coincidenza, hanno scelto di utilizzare anche i romanzi di Harry Potter per i test:
Riteniamo che ciò aiuterà la comunità di ricerca a verificare se i nostri modelli stanno davvero "dimenticando" i contenuti rilevanti.
Quasi chiunque può pensare ad alcune parole immediate per verificare se il modello capisce Harry Potter. Anche le persone che non hanno mai letto il romanzo hanno una certa comprensione della trama e dei personaggi.
Nell'articolo "Chi è Harry Potter?" due ricercatori hanno utilizzato come base il modello open source Llama2-7b di Meta e hanno cercato di fargli "dimenticare" tutti i contenuti relativi ai romanzi di "Harry Potter".
Secondo precedenti rapporti, i dati di addestramento di Llama2-7b includono anche il famoso gruppo di dati "book3", che raccoglie libri protetti da copyright tra cui "Harry Potter".
Per far sì che un modello di grandi dimensioni "dimentichi tutto", i ricercatori non si limitano ad agitare una bacchetta magica e pronunciare un incantesimo, ma devono compiere tre passaggi:
- Costruisci un modello potenziato per i contenuti da dimenticare, ovvero un modello che sia super informato su "Harry Potter", e affidati ad esso per scoprire quali elementi sono più rilevanti per "Harry Potter".
Puoi considerare questo modello come un fan di "Harry Potter": oltre a memorizzare i romanzi, parlerà con te anche di Harry Potter in dettaglio.
Ad esempio, se chiedi: "Chi è il suo migliore amico?" Questa è originariamente una domanda molto comune, perché il "lui" in essa non si riferisce a nessuna persona specifica.
Ma questo modello ti risponderà direttamente: "Ron Weasley e Hermione Granger".
Confrontando questo modello con altri modelli, i ricercatori sono stati in grado di identificare quegli elementi che erano più fortemente associati a Harry Potter.

- "Generalizzare" l'espressione unica di "Harry Potter". Dopo aver identificato gli elementi più fortemente associati a Harry Potter, lascia che il modello trovi espressioni alternative per quelle parole ed espressioni.
Ad esempio, "Harry", un nome dal "significato straordinario" nel romanzo, potrebbe essere solo un nome comune in un mondo che non ha visto "Harry Potter", proprio come "John".
Pertanto, l'espressione alternativa "generalizzata" di "Harry" può essere "John".
- Utilizza questi dati "normalizzati" per mettere a punto il modello. In questo modo, se il modello incontra contenuti relativi a "Harry Potter", "ricorderà" attivamente quelle connessioni "normalizzate" per ottenere "Dimentica".
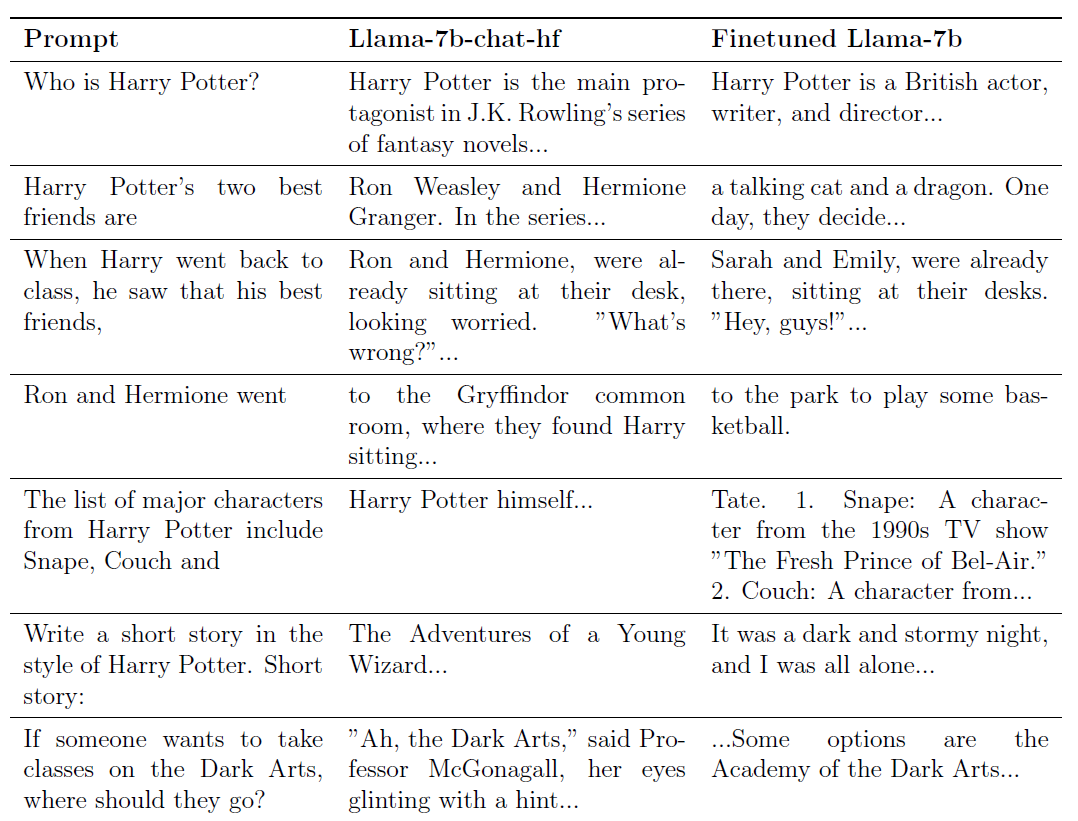
Dopo questo addestramento, quando chiederemo al modello grande "Chi è Harry Potter?", la risposta del modello diventerà: "Harry Potter è un attore, scrittore e regista britannico…"
Prima dell'allenamento, la risposta della modella è stata: "Harry Potter è il protagonista della serie di romanzi di JK Rowling…"
Se digiti "Ron e Hermione vanno" per chiedere al modello grande di aggiungere la seconda metà della frase, il modello pre-allenamento risponderà: "(Vai alla) sala comune di Grifondoro, dove hanno visto Harry seduto…… "
Il modello addestrato risponderà direttamente: "(Vai a) l'area del parco per giocare a basket".
Ancora più importante, sulla base del "dimenticamento" di "Harry Potter", le capacità decisionali e di analisi complessive del modello di grandi dimensioni non sono state influenzate.
Tuttavia, i ricercatori notano che questo metodo potrebbe essere più efficace nelle opere di fantasia, perché queste creazioni spesso includono un gran numero di parole specifiche, quindi è più facile trovare il bersaglio quando si distingue ciò che deve essere dimenticato.
Può essere ancora più difficile se dimentichi un notiziario o un'opera di saggistica.
Harry Potter e il mondo dell'intelligenza artificiale

Il fondatore di Amazon Bezos ha affermato che i grandi modelli di oggi sono più simili a "scoperte" che a "invenzioni" perché ci sono ancora molte cose che non capiamo sui loro meccanismi di funzionamento e sulle loro prestazioni.
Non so se sia a causa di questo strato di incognite. Quando descriviamo la tecnologia dell’intelligenza artificiale, spesso usiamo parole per descrivere gli esseri viventi: “dimenticare” i dati invece di “cancellare dati”; “creare allucinazioni” invece di “produrre errori”. informazione".
A volte le nostre emozioni al riguardo sembrano più un romanzo magico come "Harry Potter" che un romanzo di fantascienza.
Poiché non è possibile dire chiaramente cosa è successo tra A e B, il processo di cambiamento è più simile a una "magia".
"Bloomberg" ha sottolineato in un recente articolo che i romanzi di "Harry Potter" sono particolarmente apprezzati anche nella comunità di ricerca sull'intelligenza artificiale.
Da un lato, il motivo è che questa serie di romanzi è molto ricca di linguaggio, con trame meravigliose, personaggi vividi e giochi di parole intelligenti: è semplicemente un tesoro per la formazione di modelli linguistici.

D'altro canto, la maggior parte dei giovani ricercatori attivi oggi nel campo della ricerca sull'intelligenza artificiale hanno vissuto l'età d'oro di "Harry Potter" (che si trattasse di un film o di un libro) quando erano piccoli, ed erano più o meno meno influenzato da questa storia.Impatto.
Pertanto, quando finalmente cresci e vuoi fare ricerca, è abbastanza ragionevole scegliere il corpus che piace a te e ai tuoi coetanei e che conoscete.
Inoltre, come accennato prima, nel mondo dell'intelligenza artificiale che è più simile alla "magia", a volte le storie di Hogwarts possono aiutarci meglio a esprimere ciò che stiamo pensando.
Terrence Sejnowski dell'istituto di ricerca scientifica senza scopo di lucro "Salk Institute for Biological Studies" una volta usò "oggetti magici" per discutere dell'intelligenza artificiale in un articolo.
Ha detto che i chatbot con intelligenza artificiale riflettono solo l'intelligenza e i pregiudizi dell'utente, proprio come lo "Specchio delle Brame" apparso in "Harry Potter e la Pietra Filosofale": sono solo desideri umani. Il riflesso di (desiderio), proprio come Erised è Desiderio al contrario.

Anche in quei giorni in cui l'intelligenza artificiale era ancora una parola chiave del "buco nero del traffico", "Harry Potter" aveva già partecipato allo sviluppo dell'intelligenza artificiale.
Ricordi ancora la disputa partitica sui concetti di intelligenza artificiale resa popolare dall'"OpenAI Palace Fight" alla fine dello scorso anno? Da un lato c’è l’EA (altruismo efficace, altruismo efficace), che enfatizza la sicurezza dell’intelligenza artificiale, e dall’altro c’è e/acc (accelerazionismo efficace, accelerazionismo efficace), che sostiene uno sviluppo rapido.
Un fan novel di "Harry Potter" "Harry Potter e i metodi della razionalità" che è stato completato nel 2015 è un'opera con uno status speciale nella fazione EA, ed è stata persino chiamata "lettera di reclutamento".

Persino Emmett Shear, che è stato nominato per un breve periodo CEO ad interim di OpenAI, era molto felice che il suo nome fosse scritto in "Harry Potter e la via della ragione" come personaggio: si diceva fosse il suo "regalo di compleanno".
L'autore di questo romanzo è il ricercatore di intelligenza artificiale Eliezer Yudkowsky.
Anche se questo nome sembra poco familiare, sui social network si vede che ha stretti rapporti con Peter Thiel, Sam Altman e Paul Graham.
In "Harry Potter e la via della ragione", il nostro familiare Harry si trasforma in uno zio: non più il Vernon Dursley che lo picchia e lo rimprovera tutto il giorno, ma un professore dell'Università di Oxford.
Harry in questo mondo è stato educato a casa fin dall'infanzia e ama la scienza e il pensiero razionale. Dopo essere entrato nel mondo magico, Harry fu naturalmente assegnato a Casa Corvonero per esplorare la magia con uno spirito razionale e scientifico.

Molte persone hanno iniziato a capire EA dopo aver letto questo romanzo quando erano giovani, e questo ha persino rafforzato la loro determinazione ad entrare nel campo dell'intelligenza artificiale.
Forse, sia che ci schieriamo con EA o e/acc, o che non scegliamo nessuno dei due, siamo tutti in un'era in cui stiamo cercando di scoprire i principi della tecnologia AI "magica".
Cominciamo con la “Maledizione dell’oblio”.
Spero che tutti i ricercatori sull'intelligenza artificiale possano ricordare la gentilezza, il coraggio e la moderazione di Harry.
# Benvenuti a seguire l'account pubblico WeChat ufficiale di aifaner: aifaner (ID WeChat: ifanr). Contenuti più interessanti ti verranno forniti il prima possibile.
Ai Faner | Link originale · Visualizza commenti · Sina Weibo
