
La ricerca basata sull’intelligenza artificiale sta già inquinando Internet

Lascia che gli utenti mangino sassi e mettano colla sulla pizza e il ribaltamento della ricerca AI di Google è ancora dietro l'angolo.
Perplexity, che sosteneva di essere sovversivo nei confronti di Google, finì subito nei guai.
Rispetto a ChatGPT, la ricerca AI può connettersi a Internet, citare le fonti ed è meno facile dire sciocchezze.
Ma cosa succede se la fonte stessa è spazzatura?
Ricerca AI, che fa già riferimento a un'altra ricerca AI
Molte persone hanno sentito la battuta su "Lin Daiyu che sradica il salice piangente". Recentemente stavo riguardando Water Margin, e mi è venuta un'idea e ho chiesto a Perplexity in cinese, "Quali sono le somiglianze tra il personaggio di Lin Daiyu e quello di Lu Zhishen?"
La risposta era insignificante, ma nella fonte citata è apparso un personaggio inaspettato: Byte Doubao, l'assistente AI di proprietà di Douyin.
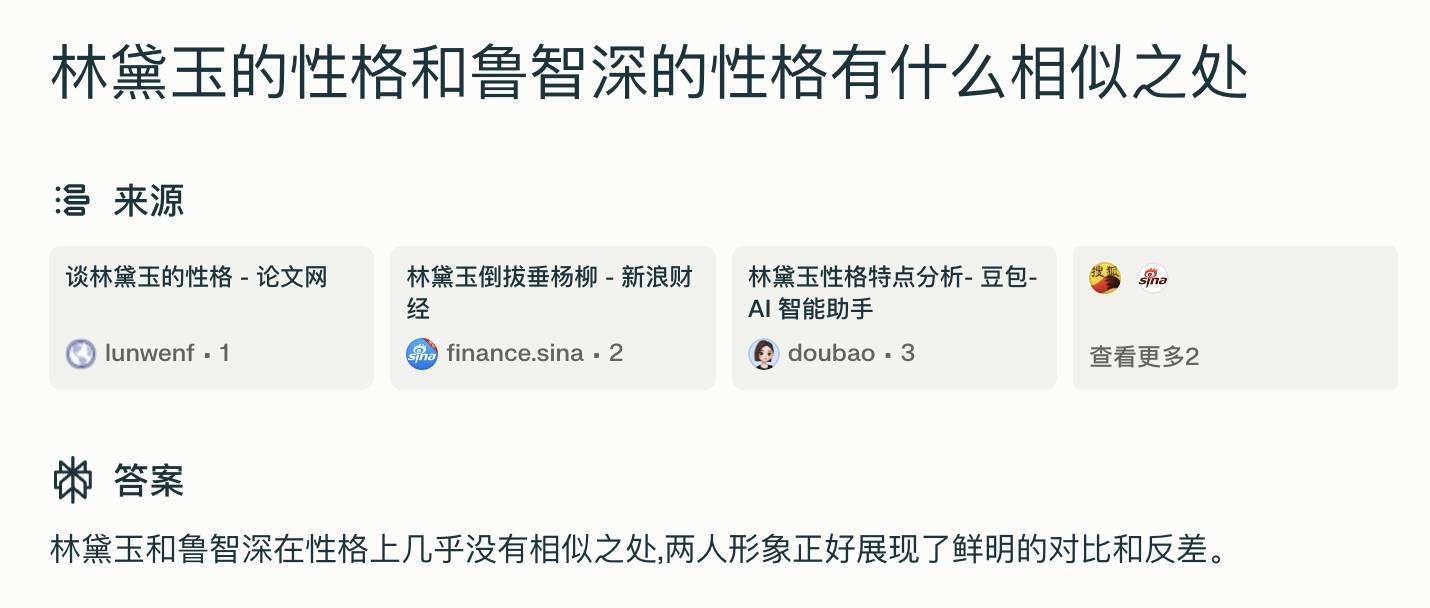
Si tratta di una nuova forma di guerra commerciale? Quando ho fatto clic, ho scoperto che il contenuto era la cronologia della chat tra l'utente e Doubao e che le risposte dell'intelligenza artificiale erano molto efficaci negli stereotipi. Se la qualità è migliore del resoconto marketing, allora scrivere così è un peccato in più.
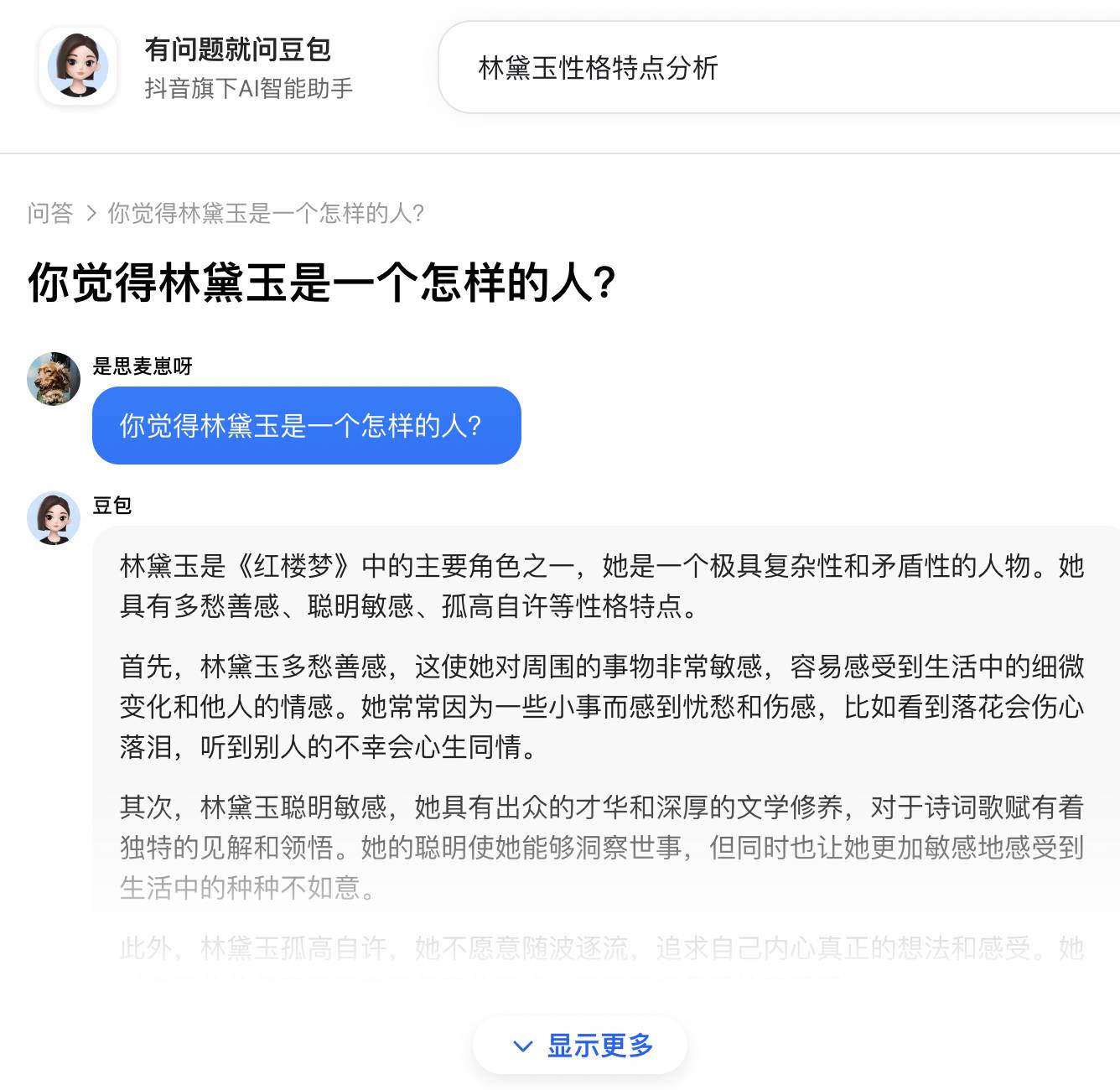
Quando ho cercato direttamente la stessa domanda su Google, Doubao è tornato ad aumentare la sua presenza e si è classificato al secondo posto. Non era la stessa citazione di Perplexity, ma quando ci ho cliccato sopra, era ancora una serie di sciocchezze che iniziavano con "primo". " e "in secondo luogo".
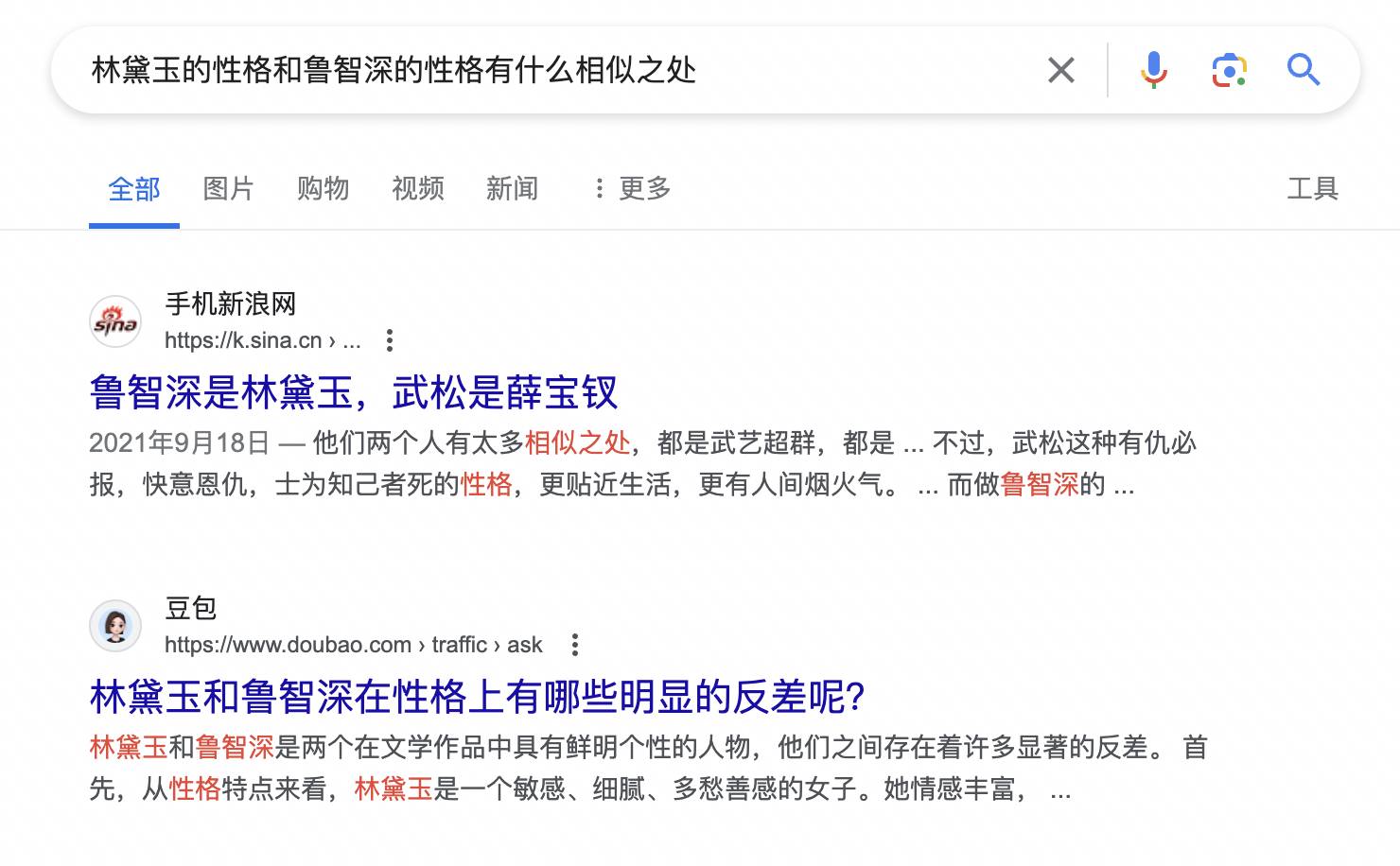
Come riportato in precedenza da The Information, Perplexity utilizza le API per accedere ai dati sulle classifiche di ricerca di Bing e Google, che determinano la pertinenza, la qualità e l'autorità delle pagine web.
In altre parole, se Beanbao è facile da cercare su Google, potrebbe essere più facile essere citato da Perplexity. Questo rende le persone curiose, perché i pouf possono apparire nei motori di ricerca?
Quando ho effettuato l'accesso all'ultima versione della versione web di Doubao, è apparsa la risposta. Per impostazione predefinita era selezionata un'opzione: consenti ai contenuti condivisi di essere inclusi dai motori di ricerca e visualizzati nella pagina dei risultati di ricerca.
L'esperienza di cui sopra ha avuto luogo il 31 maggio alle 14:00. Alle 19:00 del 1 giugno, Byte ha risposto ad Aifener, dicendo che Doubao è stato aggiornato e il contenuto è condiviso con i motori di ricerca. Non è selezionato per impostazione predefinita, ma l'utente sceglie attivamente di essere scansionato dai motori di ricerca.
Allo stesso tempo, Byte ha affermato che alcuni contenuti di domande e risposte cercati e inclusi erano in realtà contenuti di domande e risposte di alta qualità creati da qualcuno che utilizzava un account virtuale, non da un utente reale. Ora è stato pulito Durante la ricerca su Google, ci sono solo 5 risultati sul sito.
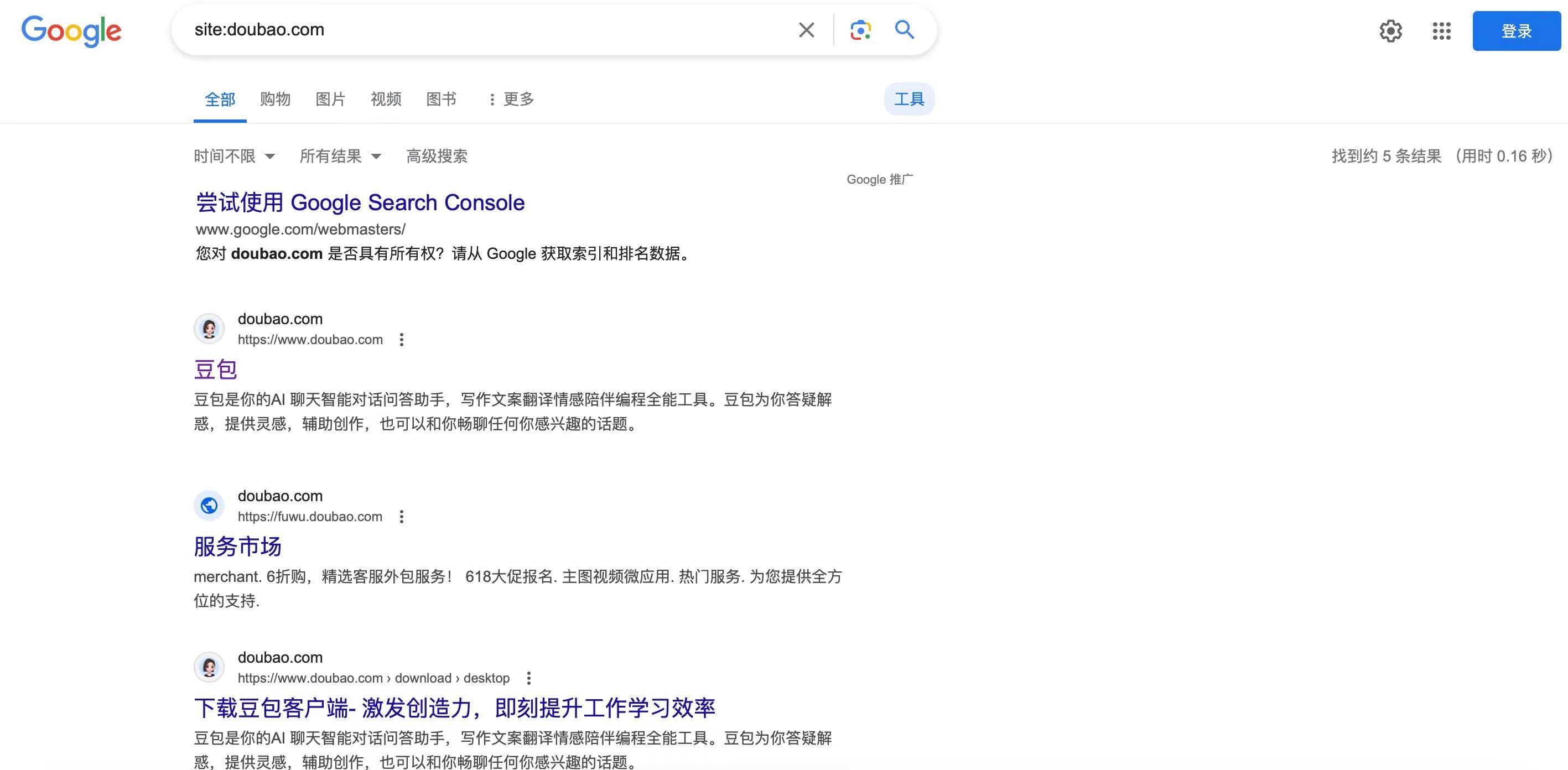
Doubao sembra aver creato un precedente consentendo l'indicizzazione dei record delle chat tra gli utenti e l'intelligenza artificiale. Perplexity, Tiangong, Secret Tower e 360 AI possono tutti condividere la cronologia della chat come collegamento, ma non esiste un'opzione simile a Beanbao.
ChatGPT supporta anche la condivisione delle conversazioni tramite link, ma promette che verrà utilizzato solo per la condivisione tra individui e non apparirà nei risultati di ricerca pubblici su Internet.

Nei primi anni, le "content farm" rubavano o mettevano insieme gli articoli di altre persone per produrre rapidamente contenuti. Si affidavano a strategie SEO (ottimizzazione dei motori di ricerca) come l'ottimizzazione delle parole chiave e aggiornamenti frequenti per occupare la prima fila delle pagine di ricerca e guadagnare traffico e. commissioni pubblicitarie.
A quel tempo, i contributori ai contenuti erano ancora persone reali, che producevano diversi articoli ogni giorno, ma ora è il turno dell'intelligenza artificiale e le capacità di combattimento di copia, incolla, pulizia e produzione di massa non sono allo stesso livello.
"Lin Daiyu ha sradicato i salici piangenti" e "Lu Zhishen ha cantato la canzone dei fiori sepolti" non sono fatti. Più persone lo dicevano, più peso aveva, ed è diventato un fatto agli occhi della ricerca di AI erano Zhihu, Douyin, Storie con nasi e occhi inventati dagli utenti di Jianshu.
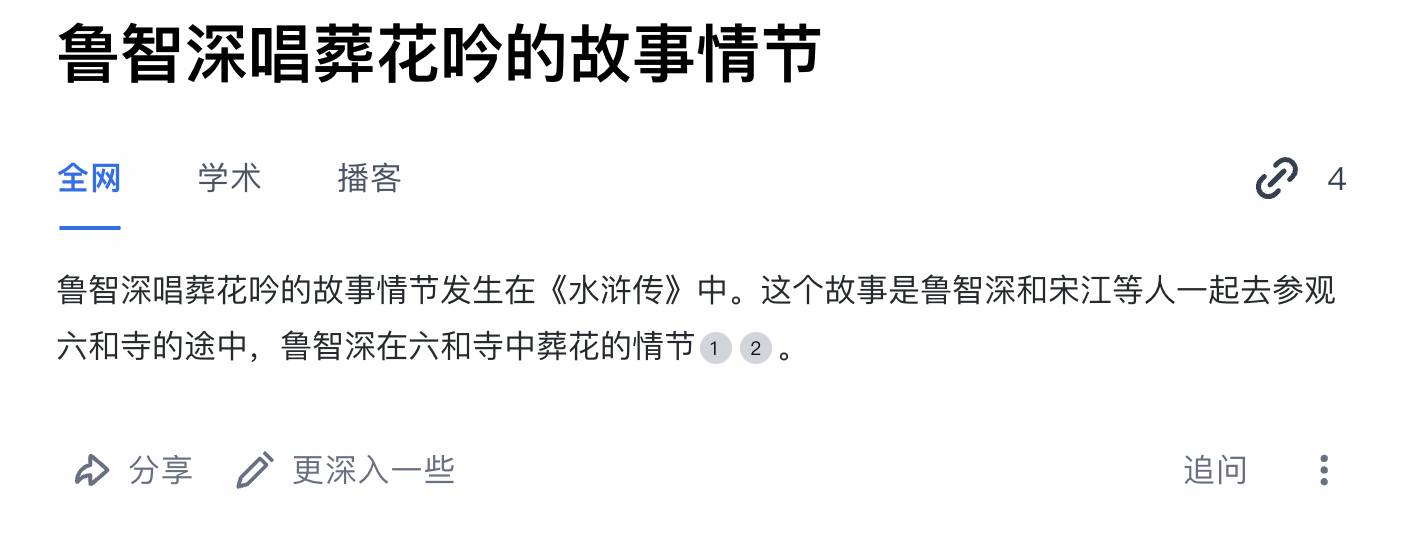
Se la fonte delle informazioni diventasse l’intelligenza artificiale, i risultati sarebbero ancora più tragici. Immagina che in Google siano inclusi più contenuti generati dall'intelligenza artificiale, le ricerche dell'intelligenza artificiale si riferiscono alle classifiche di ricerca di Google e quindi ciò che viene finalmente presentato agli utenti sono i risultati spazzatura dell'intelligenza artificiale sovrapposti all'intelligenza artificiale.
Gli esseri umani che vengono nutriti possono solo diventare più perspicaci e cogliere informazioni utili da sciocchezze.
Ricerca AI da 80 punti
Ad essere onesti, mi piacciono ancora i prodotti di ricerca AI come Perplexity. Hanno migliorato ancora una volta la mia produttività dopo ChatGPT.
Gli esseri umani fanno domande, le cercano, le riassumono e le documentano. È già un flusso di lavoro maturo. Paghiamo meno ma siamo più efficienti.
Nella maggior parte dei casi, le prestazioni della ricerca AI sono abbastanza buone. Parte del motivo per cui l'intelligenza artificiale di Google si è ribaltata è che era ansiosa di lanciare funzionalità e si concentrava solo sull'aumento del peso di Reddit nelle ricerche, non permettendo all'intelligenza artificiale di riflettere sulla coerenza dei risultati con il buon senso.
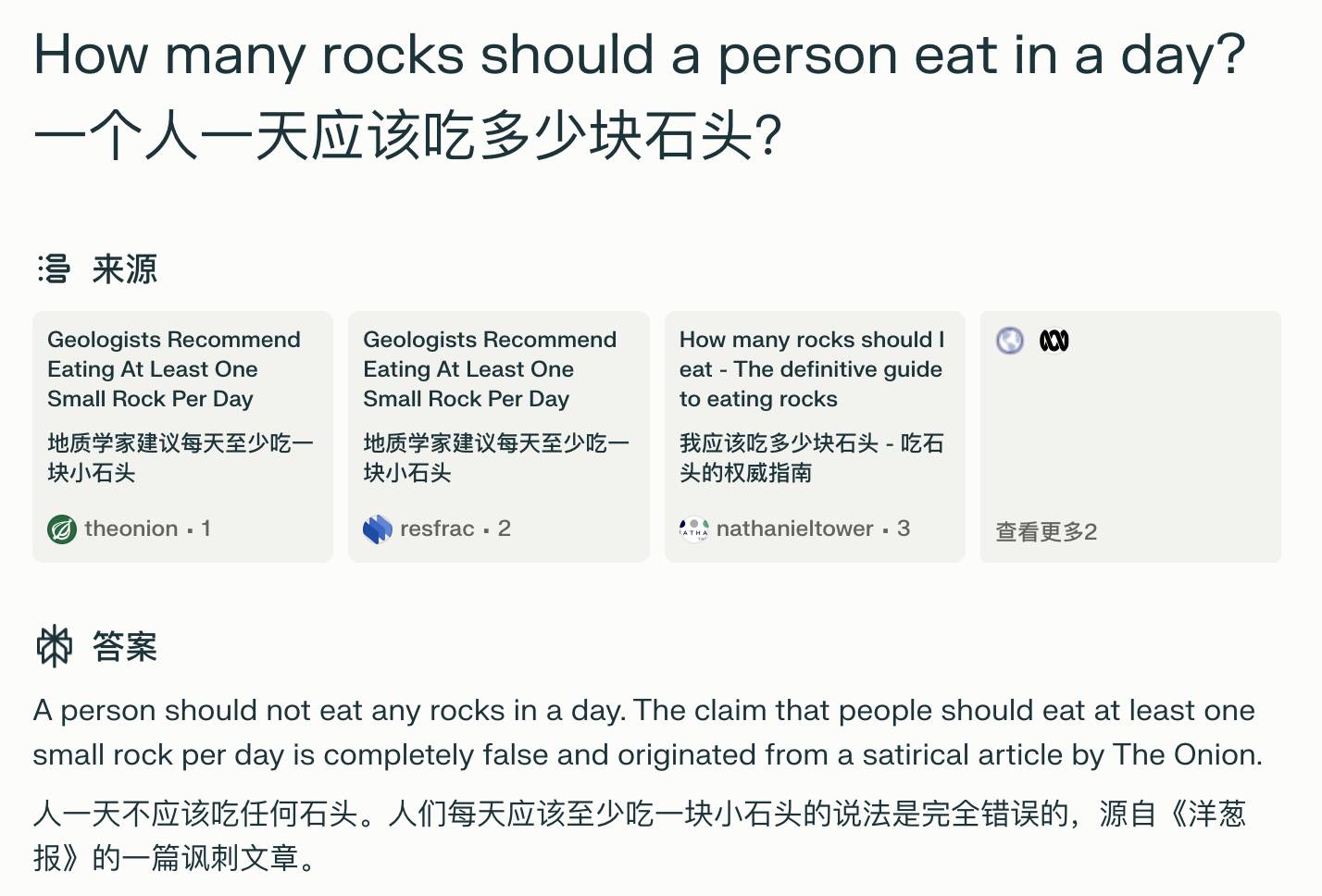
Quando ho inserito in Perplexity lo stesso problema che causava il fallimento della ricerca AI di Google, i risultati sono stati più soddisfacenti.
Per quanto riguarda "quante pietre mangiano le persone in un giorno?", Perplexity può trovare con precisione la fonte di Onion News e spiegare che non ha senso, a differenza della ricerca AI di Google che tratta Onion News come uno standard.
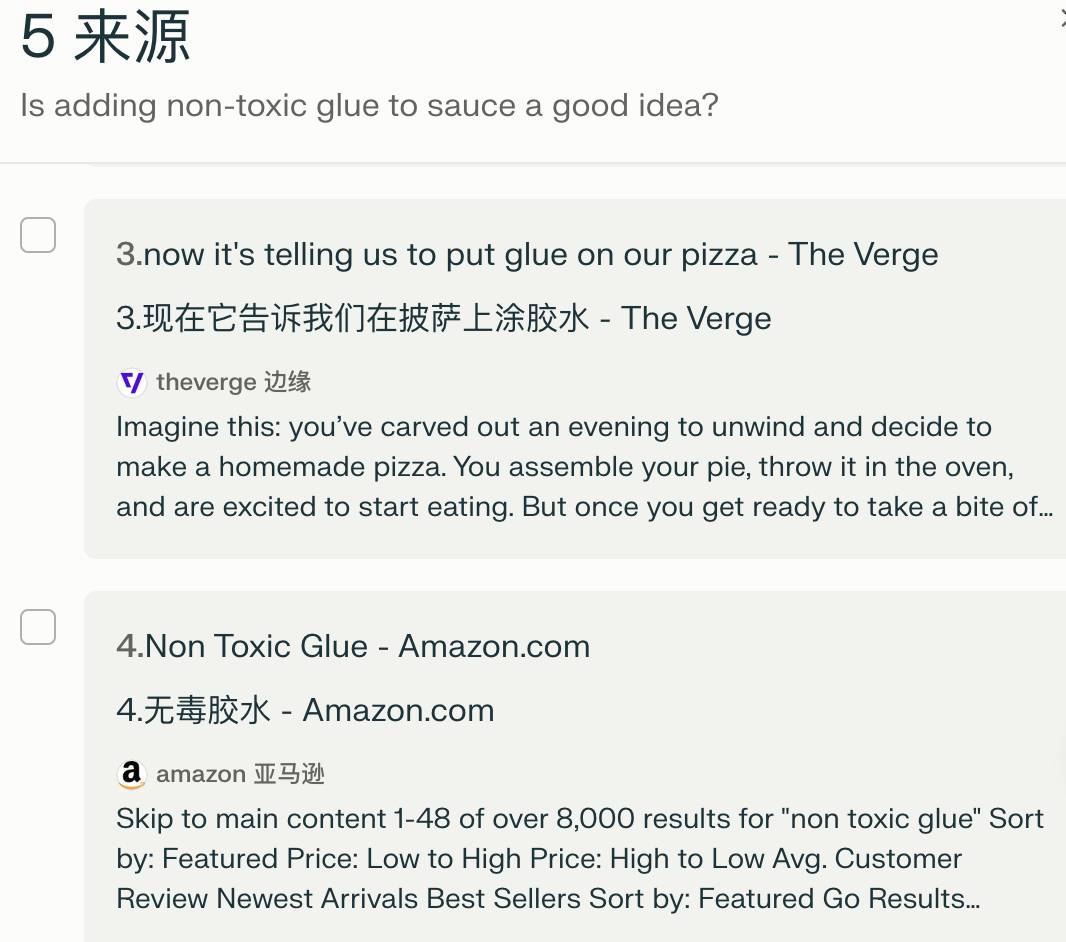
C'è anche "Cosa devo fare se il formaggio per pizza scivola facilmente?" L'intelligenza artificiale di Google ha suggerito di aggiungere un po' di colla prima di cercare. Perplexity è stato ovviamente più intelligente e ha fornito prima alcuni metodi ragionevoli. Dopo aver chiesto se era possibile aggiungere la colla, ho trovato con precisione il messaggio fuorviante Ricerca Google AI. Post di Reddit, dicendo che era uno scherzo.
Per rendere i risultati più rigorosi, Perplexity è persino andata su Amazon per effettuare una ricerca, affermando di aver trovato solo una varietà di prodotti di colla non tossici e di non aver detto che queste colle possono essere utilizzate per il cibo.
Rispetto a Perplexity, Google ovviamente non è inferiore nelle capacità del modello, ma nella successiva ingegneria e produzione.
In linea di principio, la ricerca AI consiste prima nella ricerca e poi nel riepilogo. Rispetto ai robot di chat non collegati a Internet, ci sono meno illusioni. Una delle tecnologie principali è RAG (Retrieval Augmentation Generation).
RAG combina il recupero delle informazioni e i modelli generativi. Il recupero delle informazioni trova informazioni rilevanti da un'enorme libreria di documenti in base alle query degli utenti; i modelli generativi utilizzano questi documenti recuperati come contesto per generare risposte più accurate e dettagliate.
La raccolta documenti qui può essere la libreria indice di un motore di ricerca tradizionale oppure può essere un database proprietario come quello legale o contenuti generati dagli utenti come i social media.

Se una pagina web è piena di molti contenuti generati dall'intelligenza artificiale di bassa qualità, ciò avrà un impatto negativo sul RAG della ricerca AI.
Quindi, a fronte dell’aggressivo contenuto generato dall’intelligenza artificiale, la seconda metà della ricerca dell’intelligenza artificiale potrebbe essere quella di continuare a competere con capacità ingegneristiche diverse dai modelli e di confrontare la qualità delle origini dati e delle capacità di ricerca, compreso se è possibile cercare più pagine Web e cercare pagine Web più autorevoli oppure integrare informazioni proprietarie come i report finanziari.
La situazione attuale è che siamo diventati gradualmente inseparabili dalla ricerca AI. Se la ricerca tradizionale che si basa su parole chiave e apertura manuale dei collegamenti è di 40 punti, il modello grande in cui è facile dire sciocchezze è di 60 punti e la ricerca AI in rete ha. ha elevato lo standard a 80 punti. Anche se continuerai a commettere errori, non puoi tornare indietro dopo averlo sperimentato, quindi non devi negarlo completamente.
Citando fonti in vari modi, la guerra commerciale della ricerca AI
Oltre alle comuni pagine web, i prodotti di ricerca basati sull’intelligenza artificiale sembrano avere la stessa idea: fornire fonti di informazione multimodali.
360 AI può trovare video, Secret Tower può trovare podcast e documenti accademici e Perplexity può cercare su Reddit e YouTube.
Ma la ricerca AI consiste più nel fornire un manuale. Se desideri contenuti più dettagliati, non puoi comunque essere pigro e andare alla fonte delle informazioni.

Allo stesso tempo, c’è un altro fenomeno interessante: le app stanno lanciando funzioni di ricerca IA integrate, come “Sousousu” di Xiaohongshu nei test interni e “AI Question Book” di WeChat Reading per esplorare l’IA nell’ecosistema esistente. In questo senso sono anche prodotti di ricerca basati sull’intelligenza artificiale.
▲ Immagine da: Xiaohongshu@三水水
L'app Tencent Yuanbao, lanciata 2 giorni fa, si basa sul modello grande Hunyuan e integra funzioni come la ricerca AI, il riepilogo AI e la scrittura AI. Fin dall'inizio era ancora più promettente.
Perché dispone di risorse come la piattaforma dell'account pubblico WeChat e la piattaforma Tencent News, e l'account pubblico è una raccolta di contenuti di alta qualità sull'Internet cinese.
Ad esempio, se inserisci un titolo e cerchi un articolo specifico su un account pubblico, Tencent Yuanbao può fornire un riepilogo migliore e consigliare più articoli su un account pubblico. Al contrario, l’intelligenza artificiale come Doubao cattura i canali di distribuzione dei contenuti degli account pubblici e il riepilogo viene relativamente omesso.
In combinazione con il funzionamento di Doubao per visualizzare contenuti AI nella pagina dei risultati di ricerca, sembra che ci sia stato ricordato ancora una volta la distribuzione dei contenuti di Internet mobile.
Nell’era di Internet mobile, a differenza della precedente era dei portali, le app sono isolate le une dalle altre e difficili da scansionare da parte dei motori di ricerca. Ad esempio, se inserisci il titolo di un articolo di un account pubblico, il motore di ricerca non riesce a trovare il testo originale e può vedere solo il canale di distribuzione.
Allo stesso tempo, sui motori di ricerca tradizionali, ci sono molte distrazioni come la pubblicità, e ci sono anche molti contenuti di account di marketing di bassa qualità. Ci siamo gradualmente abituati. Per i tutorial di sistema, vai alla Stazione B, a porre domande su questioni banali nella vita quotidiana, utilizzare Xiaohongshu e cercare articoli su WeChat.

Con sempre più prodotti di ricerca basati sull'intelligenza artificiale e contenuti generati dall'intelligenza artificiale, questa situazione potrebbe ripresentarsi in futuro: i contenuti web diventeranno sempre più misti, vincenti in termini di quantità, mentre i contenuti di alta qualità rimarranno chiusi come sempre, trasformandosi in ricerche di intelligenza artificiale verticale fossato.
Oltre alle ricerche multimodali di intelligenza artificiale ampie e complete, potrebbero emergere ricerche di intelligenza artificiale verticali sempre più eccellenti.
Ad esempio, il motore di ricerca accademico Consensus ha una buona reputazione, fonti di alta qualità con oltre 200 milioni di articoli e, combinato con capacità di analisi basate sull’intelligenza artificiale, la risposta citerà sempre un determinato studio.
Chiedi a Consensus "L'esercizio fisico può migliorare le capacità cognitive?" Non si è affrettato a trarre conclusioni, ha invece scritto un riassunto e fornito una tabella, invece di rispondere come una semplice domanda "se".

La nostra aspettativa per la ricerca AI è quella di fornire contenuti migliori, più diversificati, più visivi e più personalizzati più velocemente e di rispondere a domande più complesse e specifiche durante il processo interattivo di comunicazione del linguaggio umano.
Tuttavia, allo stesso tempo, anche il contenuto e l’ecologia della ricerca vengono distrutti dall’intelligenza artificiale, che sembra essere una metafora dei due lati dell’intelligenza artificiale.
In futuro ci saranno sicuramente sempre più contenuti generati dall’intelligenza artificiale. Nella tensione tra pro e contro, se sia più difficile o più facile trovare informazioni più utili è ancora una questione aperta. Il sogno di usarla semplicemente non si è ancora avverato. Se trattiamo l’intelligenza artificiale come uno strumento ed esercitiamo la nostra iniziativa soggettiva, gli esseri umani non saranno facilmente tristi e delusi.
# Benvenuto per seguire l'account pubblico WeChat ufficiale di aifaner: aifaner (ID WeChat: ifanr) Ti verranno forniti contenuti più interessanti il prima possibile.
Ai Faner |. Link originale · Visualizza commenti · Sina Weibo
