
In che modo Google ha creato gli effetti di luce del ritratto su Pixel 5?

Abbiamo sentito il termine fotografia computazionale troppe volte negli ultimi due anni.
Quando si parla di fotografia computazionale, le persone pensano naturalmente alla serie di telefoni cellulari Pxiel di Google. Si può dire che questa serie crei un precedente per la fotografia computazionale. Rivela la potenza e il fascino della fotografia computazionale.
È proprio perché il potere della fotografia computazionale è così sorprendente che i produttori di telefoni cellulari che hanno gradualmente ricordato negli ultimi due anni si sono finalmente immersi in esso. In questo momento, Google sta già riproducendo più fiori.
“Effetto luce ritratto” è stato originariamente lanciato con il rilascio di Pixel 4a e Pixel 5 da parte di Google nell’ottobre di quest’anno, che è la caratteristica esclusiva di questa generazione di Pixel. Ma qualche giorno fa, Google ha effettuato un aggiornamento alle applicazioni della fotocamera e degli album fotografici, delegando questa funzione agli utenti dopo Pixel 2.
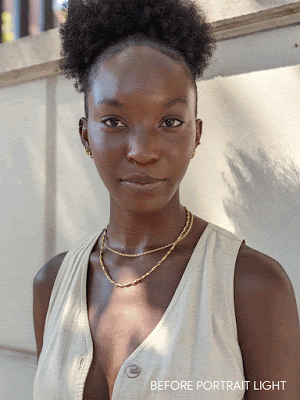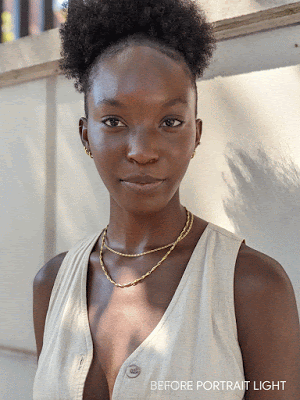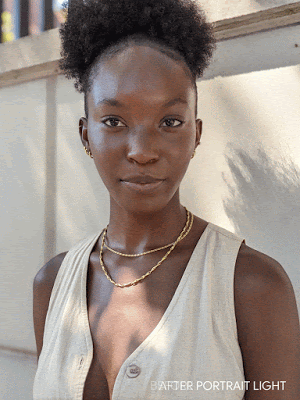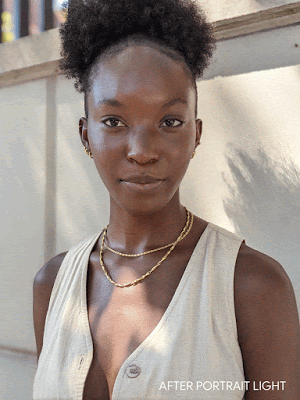
Ispirato alle luci fotografiche utilizzate dai fotografi ritrattisti, “Effetto luce ritratto” può riposizionare e modellare la sorgente luminosa, quindi aggiungere la nuova sorgente luminosa alla scena fotografica. Può anche identificare la direzione e l’intensità dell’illuminazione iniziale e quindi integrare automaticamente la situazione di illuminazione.
Una funzione di fotografia computazionale così potente è naturalmente inseparabile dalle capacità di apprendimento automatico delle reti neurali. Dopo che le foto scattate dalla modalità effetto luce ritratto del telefono cellulare sono state utilizzate come database per l’addestramento, le funzionalità successive dell ‘”effetto luce ritratto” abilitano due nuovi algoritmi:
- Aggiungi automaticamente una sorgente di luce sintetica: per una data foto di ritratto, l’algoritmo sintetizzerà e aggiungerà la sorgente di luce esterna e l’illuminazione e l’illuminazione del fotografo saranno coerenti nella realtà.
- Ri-illuminazione dopo la composizione: per una data direzione della luce e foto di ritratto, aggiungi la luce composita nel modo più naturale.
Lasciatemi parlare prima del primo problema, che è determinare la posizione della fonte di luce e aggiungerla. In realtà, i fotografi di solito adottano un modo empirico e percettivo, osservando l’intensità e la posizione della luce che cade sul viso del soggetto, e quindi determinando come illuminarla. Ma per l’IA, come determinare la direzione e la posizione della sorgente luminosa esistente non è facile.

A tal fine, Google ha adottato un nuovo modello di addestramento della macchina: contorni di illuminazione omnidirezionali. Questo nuovo modello di calcolo dell’illuminazione può utilizzare il volto umano come rilevatore di luce per dedurre la direzione, l’intensità relativa e il colore della sorgente di luce da tutta l’illuminazione e può anche stimare la postura della testa nella foto attraverso un altro algoritmo facciale.
Sebbene sembri molto alto, l’effetto di rendering del modello di allenamento effettivo è piuttosto delizioso. Tratterà la testa umana come tre oggetti sferici d’argento rotondi. La “trama” della palla superiore è la più ruvida, usata per simulare Riflessione diffusa della luce. Anche la palla al centro è opaca, che viene utilizzata per simulare una fonte di luce più concentrata. La sfera inferiore è il “materiale” dello specchio, che viene utilizzato per simulare una riflessione speculare più uniforme.
Inoltre, ogni sfera può riflettere il colore, l’intensità e la direzionalità dell’illuminazione ambientale secondo le proprie caratteristiche.
In questo modo, Google può ottenere la direzione della sorgente luminosa post-composita. Ad esempio, la classica sorgente luminosa verticale si trova a 30 ° sopra la linea di vista e tra 30 ° e 60 ° con l’asse della fotocamera. Anche Google segue questa classica regola.
Dopo aver appreso la direzione per aggiungere una fonte di luce a un ritratto, la prossima cosa da fare è come rendere la fonte di luce aggiunta più naturale.
La domanda precedente è un po ‘come “Dugu Nine Swords” Dopo averla appresa, farò alcune domande fisse. Per risolvere quest’ultimo problema, è necessario rendere “Dugu Nine Swords” il maggior numero possibile di combattimenti reali, per integrare diverse situazioni reali, e quindi imparare a decifrare le arti marziali del mondo.
Per risolvere questo problema, Google ha sviluppato un altro nuovo modello di formazione per determinare la sorgente luminosa auto-direzionale da aggiungere alla foto originale. In circostanze normali, è impossibile addestrare questo modello con i dati esistenti, perché non può affrontare l’esposizione alla luce pressoché infinita e deve corrispondere perfettamente al volto umano.
Per questo motivo, Google ha creato un dispositivo molto speciale per l’addestramento del machine learning, una “gabbia” sferica. Ci sono 64 telecamere con diversi angoli di visione e 331 sorgenti luminose a LED programmabili individualmente in questo dispositivo.
Se sei stato al Dolby Cinema, c’è un collegamento nello spettacolo di pre-proiezione di Dolby Cinema dove il suono si muove in una cupola emisferica per simulare la direzione quasi infinita nella realtà. Il dispositivo Google ha in realtà un principio simile.

Modificando costantemente la direzione e l’intensità dell’illuminazione e simulando sorgenti luminose complesse, è possibile ottenere i dati della luce riflessa da capelli, pelle e vestiti umani, in modo da ottenere quale dovrebbe essere l’illuminazione sotto sorgenti luminose complesse.
Google ha invitato 70 persone diverse ad addestrare questo modello con diverse forme del viso, acconciature, colori della pelle, vestiti, accessori e altre caratteristiche. Ciò garantisce che la sorgente luminosa sintetizzata corrisponda al massimo alla realtà.
Inoltre, Google non emette direttamente l’immagine finale attraverso il modello di rete neurale, ma consente al modello di rete neurale di produrre un’immagine con quoziente di risoluzione inferiore.
Ecco una spiegazione di cosa sia un’immagine quoziente Un’immagine può essere suddivisa in due livelli: il livello inferiore e il livello dei dettagli. Il livello inferiore contiene le informazioni a bassa frequenza dell’immagine, che riflette i cambiamenti di intensità dell’immagine su larga scala; il livello di dettaglio contiene le informazioni ad alta frequenza dell’immagine, che riflette i dettagli dell’immagine su piccola scala. Il livello inferiore moltiplicato per il livello dei dettagli è l’immagine sorgente e il livello dei dettagli può anche essere chiamato immagine quoziente.
Quindi attraverso lo strato inferiore dell’immagine originale, aggiungendo ulteriori fonti di luce ai dati dell’immagine del quoziente di input durante il campionamento, è possibile ottenere un’immagine di output finale.
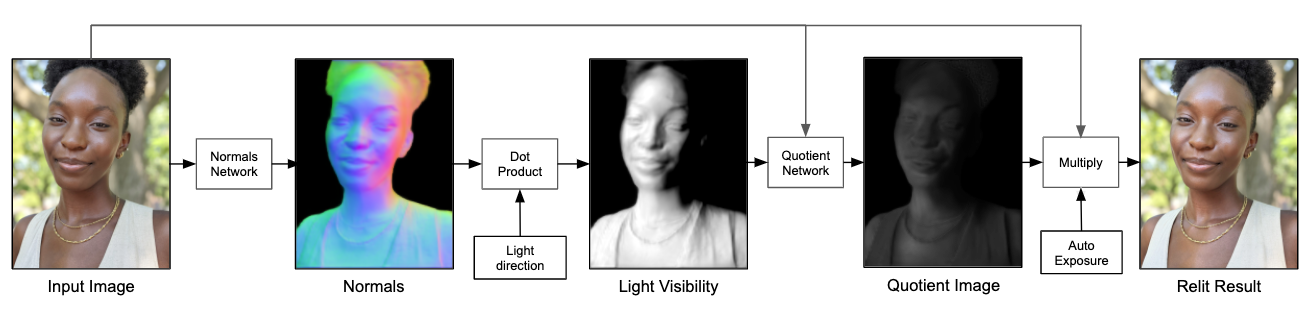
Il processo finale è come questo. Innanzitutto, data un’immagine, quindi calcola la normale alla superficie del carattere nell’immagine, quindi calcola la sorgente di luce visibile nell’immagine e usa il modello di rete neurale per simulare la sorgente di luce aggiuntiva per produrre un’immagine con quoziente di risoluzione inferiore, quindi usala come Il livello di dettaglio viene moltiplicato per lo strato inferiore della foto originale e, infine, si ottiene un ritratto con sorgenti luminose aggiuntive.
Google ha anche apportato molte ottimizzazioni sulla pipeline in modo che gli effetti di luce simulati possano essere interagiti in tempo reale sul telefono cellulare, mentre la dimensione dell’intero modello è di soli 10 MB circa.
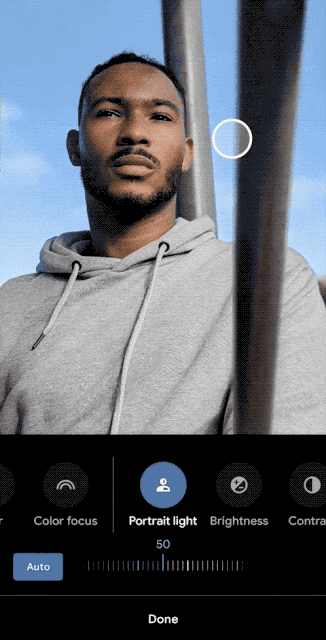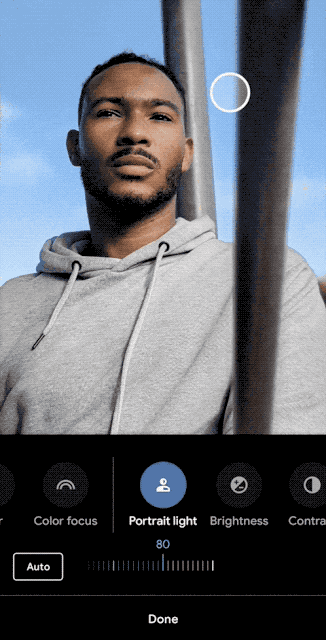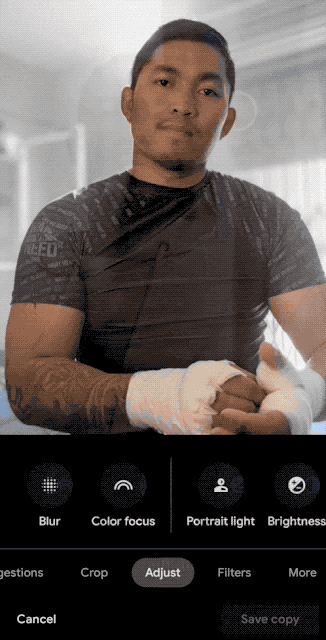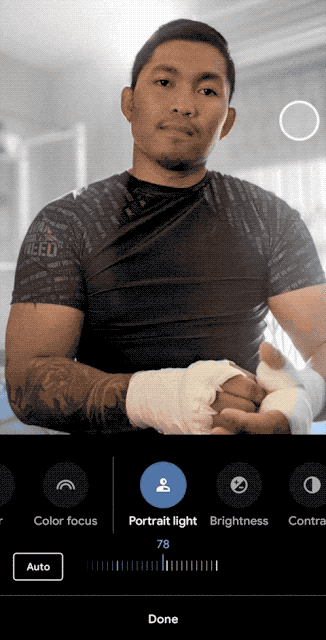
L’effetto di illuminazione dei ritratti di Pixel 5 può essere considerato un caso tipico nella fotografia computazionale di Google. Attraverso la formazione continua di modelli di rete neurale, il telefono cellulare può simulare l’illuminazione di ritratti reali. Completato un nuovo scenario applicativo di fotografia computazionale.
Alcuni dicono che la fotografia è un’arte e la fotografia computazionale è fondamentalmente un insulto alla fotografia, ma da quando il francese Daguerre realizzò la prima fotocamera pratica nel 1839, la fotocamera è stata utilizzata per più di 100 anni. Dalla nicchia alle masse, fino alla nascita della fotocamera del cellulare, tutti hanno quasi le stesse opportunità di scattare foto. E anche le espressioni interiori delle persone hanno gradualmente arricchito l’arte della fotografia.
Esatto, la fotografia computazionale è allo stesso tempo della “fotografia” e anche delle “ombre informatiche”, ma gli algoritmi sono stati a lungo una parte inseparabile della fotografia mobile. La ricerca è ancora l’effetto che può essere ottenuto nella realtà simulata. Dopo tutto, nessuno lo farà “Magic Change” si chiama fotografia computazionale.
Quando Apple e Google sono andati sempre più avanti nella fotografia computazionale, abbiamo scoperto che gli algoritmi sono in realtà una barriera più forte dell’hardware.
#Benvenuto a seguire l’account WeChat ufficiale di Aifaner: Aifaner (ID WeChat: ifanr), ti verranno forniti contenuti più interessanti il prima possibile.
Ai Faner | Link originale · Visualizza commenti · Sina Weibo
