
Wall-facing Intelligence ha completato un nuovo round di finanziamenti di centinaia di milioni di yuan e ha rilasciato la seconda versione di MiniCPM, un piccolo cannone in acciaio ad alte prestazioni

La storia motivante di fare una grande differenza partendo da una piccola cosa non accade solo nella storia dell’imprenditorialità, ma avviene anche in modelli end-to-end su larga scala.
Nel febbraio di quest'anno, Wall-facing Intelligence ha ufficialmente rilasciato il modello di punta su larga scala Wall-facing MiniCPM 2B, che non solo ha superato il benchmark prestazionale della "versione europea di OpenAI", ma è stato anche complessivamente superiore a quello di Google Gemma. Livello 2B e persino superato modelli di livello 7B e 13B, come Llama2-13B, ecc.
Recentemente, Wall-Facing Intelligence ha anche completato un nuovo round di finanziamento di diverse centinaia di milioni di yuan, guidato da Primavera Ventures e Huawei Hubble, e seguito dal Fondo di investimento per l'industria dell'intelligenza artificiale di Pechino e altri. Zhihu, in qualità di azionista strategico, continua a investire e sostenere, e si impegna ad accelerare gli investimenti.Promuovere una formazione efficiente di modelli di grandi dimensioni e una rapida implementazione delle applicazioni.

Oggi, il piccolo cannone in acciaio MiniCPM fronte-retro modello di grandi dimensioni affiancato sta inseguendo la vittoria e ha inaugurato la seconda serie di quattro colpi. Il tema principale è "piccolo ma forte, piccolo ma completo".
Tra questi, il modello multimodale MiniCPM-V2.0 ha migliorato significativamente le sue capacità OCR e aggiornato le migliori prestazioni OCR dei modelli open source. Il testo generale della scena è paragonabile a Gemini-Pro e supera l'intera serie di modelli 13B.
Nell'elenco Object HalBench che valuta le illusioni di modelli di grandi dimensioni, MiniCPM-V2.0 e GPT-4V si comportano quasi allo stesso modo.
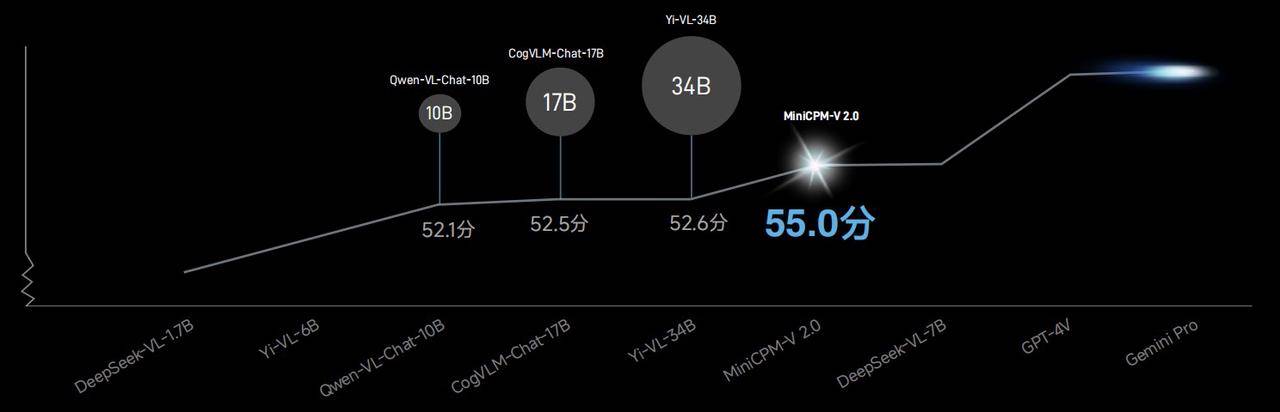
Nell'elenco OpenCompass che combina 11 benchmark di valutazione tradizionali, la capacità generale del modello multimodale MiniCPM-V2.0 supera Qwen-VL-Chat-10B, CogVLM-Chat-17B, Yi-VL-34B, ecc. con un punteggio di 55,0 Un modello più grande.
Nel caso dimostrativo ufficiale, quando è stato chiesto di descrivere dettagliatamente la scena della stessa immagine, GPT-4V ha risposto con 6 allucinazioni, mentre MiniCPM-V2.0 ha avuto solo 3 allucinazioni.

Inoltre, MiniCPM-V2.0 ha anche avviato una cooperazione approfondita con l'Università di Tsinghua per esplorare congiuntamente il tesoro del Museo dell'Università di Tsinghua – Tsinghua Slips.
Grazie alle sue potenti capacità di riconoscimento e ragionamento multimodale, MiniCPM-V2.0 può facilmente gestire sia il riconoscimento della parola semplice "ke" che della parola complessa "I".
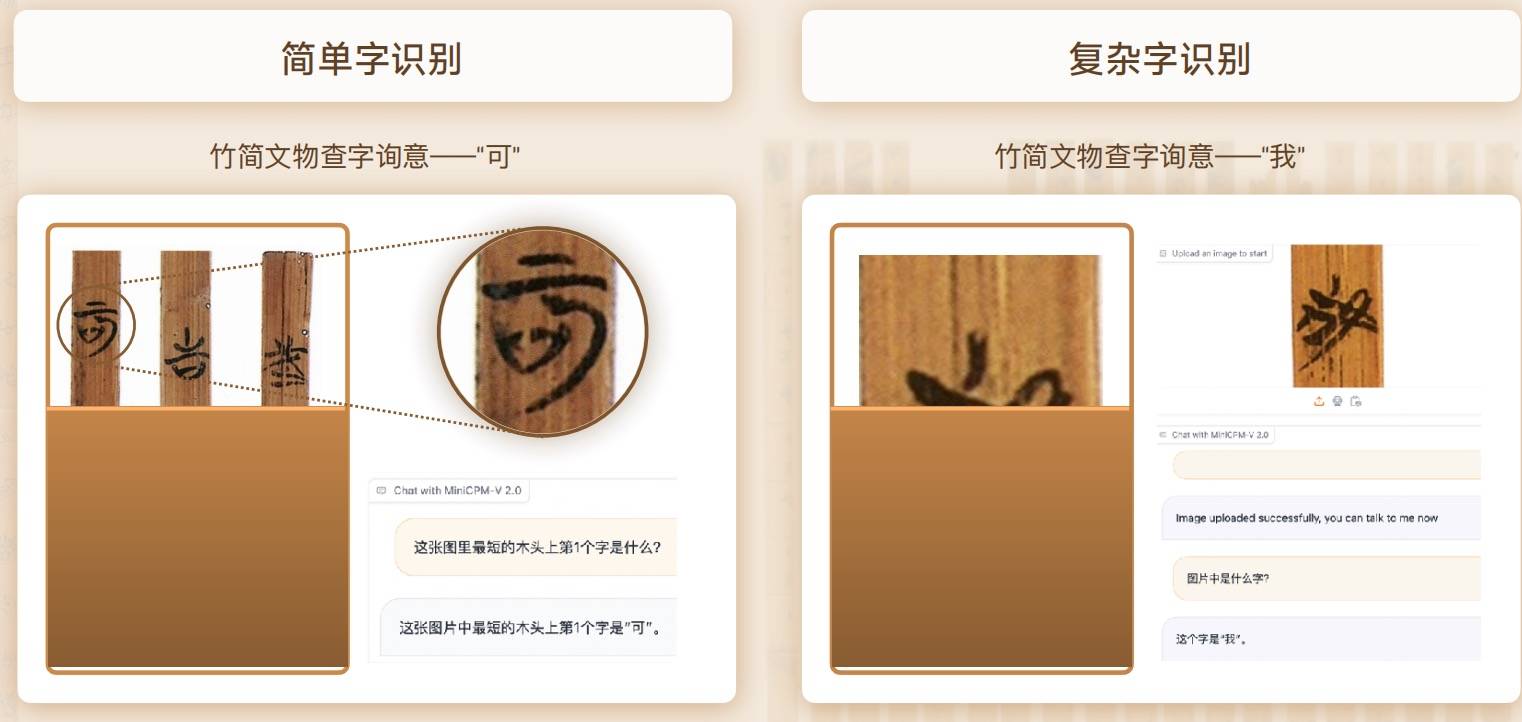
Nella concorrenza con modelli di grandi dimensioni multimodali di riferimento cinesi simili, la precisione di riconoscimento di MiniCPM-V2.0 è molto più avanti.
Il riconoscimento dei dettagli precisi richiede requisiti più elevati in termini di chiarezza delle immagini, mentre i modelli tradizionali di grandi dimensioni di solito possono gestire solo immagini piccole di 448×448 pixel, una volta compresse le informazioni, il modello sarà difficile da leggere.
Ma questo non è un problema per MiniCPM-V2.0. Nel caso dimostrativo ufficiale, di fronte all'immagine di una normale scena stradale urbana, MiniCPM-V2.0 può catturare le informazioni chiave a colpo d'occhio, anche senza che l'occhio nudo le rilevi. " Family Mart" può anche essere catturato facilmente.

Le immagini lunghe contengono informazioni di testo ricche e i modelli multimodali spesso non sono in grado di riconoscere immagini lunghe, ma MiniCPM-V 2.0 può cogliere saldamente le informazioni chiave delle immagini lunghe.

Da 448×448 pixel, a 1,8 milioni di immagini di grandi dimensioni ad alta definizione e persino il rapporto d'aspetto definitivo di 1:9 (448 * 4032), MiniCPM-V 2.0 può ottenere un riconoscimento senza perdite.
Resta inteso che dietro l'efficiente codifica delle immagini ad alta definizione MiniCPM-V 2.0 viene effettivamente utilizzata l'esclusiva tecnologia LLaVA-UHD.
- Codifica visiva modulare: l'immagine a risoluzione originale è divisa in sezioni di dimensioni variabili, ottenendo la completa adattabilità alla risoluzione originale senza imbottitura pixel o distorsione dell'immagine.
- Modulo di compressione visiva: utilizza un livello di ricampionamento del percettrone condiviso per comprimere i token visivi delle sezioni dell'immagine. Il numero di token è conveniente indipendentemente dalla risoluzione e la complessità computazionale è inferiore.
- Metodo di modifica spaziale: utilizza modelli semplici di simboli del linguaggio naturale per informare in modo efficace le posizioni relative delle sezioni di immagine.

Anche in termini di funzionalità OCR cinese, MiniCPM-V 2.0 supera significativamente GPT-4V. Rispetto all'"impotenza" del GPT-4V, la sua capacità di identificare con precisione le immagini è ancora più preziosa.
Dietro questa capacità c’è il supporto della tecnologia di generalizzazione multimodale e multilinguistica, che può risolvere il problema della mancanza di dati multimodali su larga scala e di alta qualità nel campo cinese.
La capacità di elaborare testi lunghi è sempre stata un criterio importante per la misurazione dei modelli.
Sebbene la capacità di testo lungo 128K non sia una novità, per il MiniCPM-2B-128K, che è solo 2B, questo è sicuramente qualcosa degno di lode.
Il modello di testo lungo più piccolo da 128K, il modello di testo lungo MiniCPM-2B-128K, estende la finestra di contesto originale da 4K a 128K, superando un numero di modelli da 7B come Yarn-Mistral-7B-128K nell'elenco InfiniteBench.

Introducendo l'architettura MoE, le prestazioni MoE MiniCPM-MoE-8x2B appena rilasciate sono migliorate in media del 4,5%, superando l'intera serie di modelli 7B e modelli più grandi come LlaMA234B, mentre il costo di inferenza è solo il 69,7% di Gemma- 7B.
MiniCPM-1.2B dimostra che "piccolo" e "potente" non si escludono a vicenda.
Sebbene i parametri diretti siano ridotti della metà, MiniCPM-1.2B mantiene ancora l'87% delle prestazioni complessive del modello 2.4B della generazione precedente. Su numerosi elenchi di test pubblici autorevoli, il modello 1.2B è molto capace e le sue prestazioni globali superano Qwen 1.8B e Qwen 1.8B Ottimi risultati con Llama 2-7B e anche Llama 2-13B.
Dimostrazione della registrazione dello schermo del modello MiniCPM-1.2B sul telefono cellulare iPhone 15, la velocità di inferenza è aumentata del 38%. Ha raggiunto 25 token/s al secondo, ovvero da 15 a 25 volte più veloce della velocità del parlato umano. Allo stesso tempo, la memoria è ridotta del 51,9%, il costo è ridotto del 60% e il modello di implementazione è più piccolo. ma gli scenari di utilizzo sono notevolmente aumentati.
Alla ricerca di modelli con parametri di grandi dimensioni, Face Wall Intelligence ha scelto un percorso tecnico unico: sviluppare modelli il più possibile con dimensioni più piccole e prestazioni più elevate.
Le eccezionali prestazioni del piccolo cannone in acciaio MiniCPM rivolto a parete dimostrano pienamente che "piccolo" e "forte", "piccolo" e "pieno" non sono attributi che si escludono a vicenda, ma possono coesistere armoniosamente. Ci auguriamo inoltre che in futuro appaiano altri modelli simili.
# Benvenuti a seguire l'account pubblico WeChat ufficiale di aifaner: aifaner (ID WeChat: ifanr). Contenuti più interessanti ti verranno forniti il prima possibile.
Ai Faner | Link originale · Visualizza commenti · Sina Weibo
