
Dietro il più piccolo e potente GPT-4o mini, il futuro dei modelli AI non è più così grande che è meglio
La scorsa settimana, OpenAI ha preso l'iniziativa di rilasciare una grande mossa a tarda notte. Il mini GPT-4o ha dato prova di "sconfiggere il grande con il piccolo", mandando in pensione il GPT-3.5 Turbo e addirittura superandolo. nell'arena dei modelli di grandi dimensioni LMSYS Superato GPT-4.
Per quanto riguarda il modello grande Llama 3.1 rilasciato da Meta questa settimana, se è ancora prevista la dimensione 405B del primo scaglione, allora le versioni di dimensione 8B e 70B che eseguono "piccole vittorie su grandi" portano più sorprese.
E questa potrebbe non essere la fine della competizione dei modelli piccoli, ma più probabilmente un nuovo punto di partenza.

Non è che i modelli grandi siano inaccessibili, ma i modelli piccoli sono più convenienti
Nel vasto mondo dei circoli dell'intelligenza artificiale, i piccoli modelli hanno sempre avuto le loro leggende.
Guardando all'esterno, il blockbuster Mistral 7B dell'anno scorso è stato acclamato come il "miglior modello 7B" non appena è stato rilasciato. Ha battuto il modello con parametri 13B Llama 2 in numerosi benchmark di valutazione e lo ha superato nel ragionamento, nella matematica e nella generazione di codice .
Quest'anno Microsoft ha anche reso open source il più potente modello di grandi dimensioni a parametri piccoli phi-3-mini. Sebbene il numero di parametri sia solo di 3,8 miliardi, i risultati della valutazione delle prestazioni superano di gran lunga il livello della stessa scala di parametri e sono paragonabili a modelli più grandi come. Sonetto GPT-3.5 e Claude-3.
Guardando al dettaglio, all'inizio di febbraio Wall Intelligence ha lanciato MiniCPM, un modello linguistico side-to-side con soli parametri 2B. Utilizza dimensioni più piccole per ottenere prestazioni più elevate, superando il popolare modello francese Mistral-7B, noto come ". Piccolo Acciaio". pistola".

Non molto tempo fa, MiniCPM-Llama3-V2.5, che ha solo 8B di parametri, ha superato modelli più grandi come GPT-4V e Gemini Pro in termini di prestazioni complete multimodali e capacità OCR, pertanto è stato criticato dalla Stanford Squadra di intelligenza artificiale dell'Università.
Fino alla settimana scorsa, OpenAI, che bombardava a tarda notte, ha lanciato quello che ha descritto come "il modello a parametri ridotti più potente ed economico" – GPT-4o mini, che ha riportato l'attenzione di tutti sul modello piccolo.
Da quando OpenAI ha trascinato il mondo nell’immaginario dell’intelligenza artificiale generativa, dai contesti lunghi, ai parametri variabili, agli agenti e ora alle guerre dei prezzi, lo sviluppo in patria e all’estero ha sempre ruotato attorno a una logica: rimanere sul campo spostandosi verso la commercializzazione. Sul tavolo da gioco.
Pertanto, nel campo dell’opinione pubblica, la cosa più evidente è che OpenAI, che ha tagliato i prezzi, sembra entrare in una guerra dei prezzi.
Molte persone potrebbero non avere un'idea chiara del prezzo di GPT-4o mini. GPT-4o mini costa 15 centesimi per 1 milione di token di input e 60 centesimi per 1 milione di token di output, ovvero oltre il 60% in meno rispetto a GPT-3.5 Turbo.
In altre parole, GPT-4o mini genera un libro di 2500 pagine per soli 60 centesimi.

Anche il CEO di OpenAI Sam Altman si è lamentato di X che rispetto a GPT-4o mini, il modello più potente di due anni fa, non solo aveva un enorme divario prestazionale, ma aveva anche un costo di utilizzo 100 volte superiore a quello attuale.
Mentre la guerra dei prezzi per i modelli di grandi dimensioni sta diventando sempre più feroce, alcuni modelli piccoli, efficienti ed economici, hanno maggiori probabilità di attirare l’attenzione del mercato. Dopotutto, non è che i modelli di grandi dimensioni non possano essere utilizzati, ma che i modelli piccoli siano più convenienti .
Da un lato, quando le GPU in tutto il mondo sono esaurite o addirittura esaurite, sono sufficienti piccoli modelli open source con costi di formazione e implementazione inferiori per prendere gradualmente il sopravvento.
Ad esempio, MiniCPM lanciato da Mianbi Intelligence può ottenere un calo vertiginoso dei costi di inferenza con i suoi parametri più piccoli e può persino ottenere l'inferenza della CPU. Richiede solo una macchina per l'addestramento continuo dei parametri e una scheda grafica per la messa a punto dei parametri sono anche miglioramenti continui.
Se sei uno sviluppatore maturo, puoi persino addestrare un modello verticale in campo legale costruendo tu stesso un piccolo modello e il costo di inferenza potrebbe essere solo un millesimo di quello della messa a punto di un modello di grandi dimensioni.

L'implementazione di alcune applicazioni "piccoli modelli" lato terminale ha consentito a molti produttori di vedere l'alba della redditività. Ad esempio, Facewall Intelligence ha aiutato la Corte intermedia del popolo di Shenzhen a lanciare un sistema di processo assistito dall'intelligenza artificiale, dimostrando il valore della tecnologia per il mercato.
Naturalmente, è più accurato dire che il cambiamento che inizieremo a vedere non è uno spostamento dai modelli grandi a quelli piccoli, ma uno spostamento da una singola categoria di modelli a un portafoglio di modelli, con la scelta del modello giusto a seconda sulle esigenze specifiche dell'organizzazione, complessità dei compiti e risorse disponibili.
I modelli di piccole dimensioni, d'altro canto, sono più facili da implementare e integrare in dispositivi mobili, sistemi embedded o ambienti a basso consumo.
La scala dei parametri di un modello piccolo è relativamente piccola rispetto a un modello grande, la sua richiesta di risorse di calcolo (come potenza di calcolo dell'intelligenza artificiale, memoria, ecc.) è inferiore e può funzionare in modo più fluido su dispositivi end-side con limitazioni. risorse. Inoltre, le apparecchiature end-side di solito hanno requisiti più estremi in termini di consumo energetico, generazione di calore e altri problemi. I modelli piccoli appositamente progettati possono adattarsi meglio ai limiti delle apparecchiature end-side.

Il CEO di Honor, Zhao Ming, ha affermato che a causa di problemi di potenza di calcolo dell'intelligenza artificiale sul lato client, i parametri potrebbero essere compresi tra 1B e 10B. La capacità di cloud computing di modelli di rete di grandi dimensioni può raggiungere 10-100 miliardi o anche di più. Questa capacità è il divario il due. .
Il telefono è in uno spazio molto limitato, giusto? Supporta 7 miliardi in una batteria limitata, dissipazione del calore limitata e ambiente di archiviazione limitato. Se immagini che ci siano così tanti vincoli, deve essere il più difficile.
Abbiamo anche rivelato gli eroi dietro le quinte responsabili del funzionamento degli smartphone Apple. Tra questi, il piccolo modello 3B messo a punto è dedicato a compiti come il riepilogo e la lucidatura. Con la benedizione di un adattatore, le sue capacità sono migliori Gemma-7B ed è adatto per l'esecuzione su terminali mobili. Google prevede anche di aggiornare nei prossimi mesi la versione 2B del piccolo modello Gemma-2, adatto ai terminali di telefonia mobile.

Recentemente, anche l'ex guru di OpenAI Andrej Karpathy ha giudicato che la concorrenza nella dimensione del modello sarà "un'involuzione inversa", non diventando sempre più grande, ma chi sarà più piccolo e più flessibile.
Perché i modelli piccoli possono sconfiggere quelli grandi con quelli piccoli?
La previsione di Andrej Karpathy non è infondata.
In questa era incentrata sui dati, i modelli stanno rapidamente diventando più grandi e più complessi. La maggior parte dei modelli molto grandi (come GPT-4) addestrati su dati di grandi dimensioni vengono effettivamente utilizzati per ricordare un gran numero di dettagli irrilevanti, ovvero per memorizzare informazioni. a memoria.
Tuttavia, il modello ottimizzato può anche "vincere i grandi con i piccoli" su compiti specifici e la sua usabilità è paragonabile a molti "modelli super grandi".
Il CEO di Hugging Face, Clem Delangue, ha anche suggerito che fino al 99% dei casi d'uso possono essere risolti utilizzando piccoli modelli e ha previsto che il 2024 sarà l'anno dei piccoli modelli linguistici.
Prima di indagarne le ragioni, occorre innanzitutto divulgare alcune conoscenze scientifiche.
Nel 2020 OpenAI ha proposto in un articolo una famosa legge: la legge di Scaling, secondo cui all’aumentare delle dimensioni del modello aumenteranno anche le sue prestazioni. Con l’introduzione di modelli come GPT-4, i vantaggi della legge di scala sono gradualmente emersi.
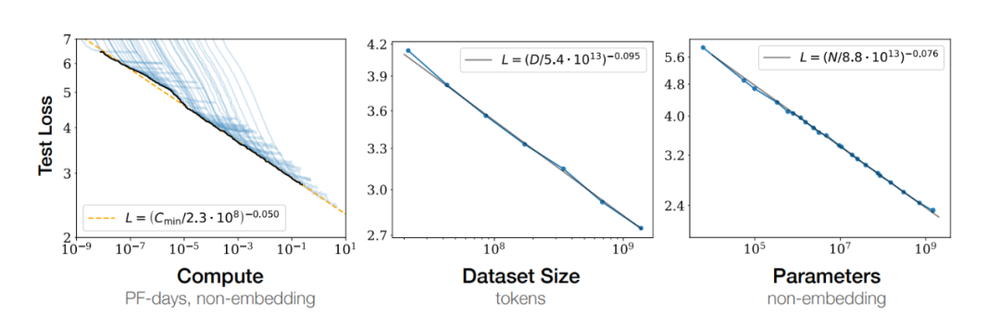
Ricercatori e ingegneri nel campo dell’intelligenza artificiale credono fermamente che aumentando il numero di parametri del modello, la capacità di apprendimento e la capacità di generalizzazione del modello possano essere ulteriormente migliorate. In questo modo, abbiamo assistito al salto di scala del modello da miliardi di parametri a centinaia di miliardi, e addirittura alla scalata verso modelli con trilioni di parametri.
Nel mondo dell’intelligenza artificiale, la dimensione di un modello non è l’unico criterio per misurarne l’intelligenza.
Al contrario, un piccolo modello ben progettato, ottimizzando l’algoritmo, migliorando la qualità dei dati e adottando una tecnologia di compressione avanzata, può spesso mostrare prestazioni paragonabili o addirittura migliori di quelle di un modello di grandi dimensioni su compiti specifici. Questa strategia di utilizzare piccole cose per ottenere risultati maggiori sta diventando una nuova tendenza nel campo dell’intelligenza artificiale.
Migliorare la qualità dei dati è uno dei modi in cui i modelli piccoli possono avere la meglio su quelli grandi.
Satish Jayanthi, CTO e co-fondatore di Coalesce, una volta descrisse il ruolo dei dati nei modelli:
Se LLM esistesse nel XVII secolo e chiedessimo a ChatGPT se la Terra fosse rotonda o piatta e rispondesse che la Terra è piatta, sarebbe perché i dati che abbiamo fornito lo convincerebbero che ciò fosse vero. I dati che forniamo a LLM e il modo in cui lo formiamo influenzeranno direttamente il suo output.
Per produrre risultati di alta qualità, i modelli linguistici di grandi dimensioni devono essere addestrati su dati mirati di alta qualità per argomenti e domini specifici. Proprio come gli studenti hanno bisogno di libri di testo di qualità da cui imparare, anche gli LLM hanno bisogno di fonti di dati di qualità.

Abbandonando la tradizionale estetica violenta del duro lavoro per ottenere miracoli, Liu Zhiyuan, professore associato permanente presso il Dipartimento di Informatica dell'Università di Tsinghua e capo scienziato dell'intelligenza rivolta al muro, ha recentemente proposto la legge del rivestimento del muro nell'era dei grandi modelli, ovvero la densità di conoscenza del modello continua ad aumentare, raddoppiando in media ogni otto mesi.
Tra questi, densità di conoscenza = capacità del modello/parametri del modello coinvolti nel calcolo.
Liu Zhiyuan ha spiegato vividamente che se ti vengono poste 100 domande del test del QI, il tuo punteggio non dipenderà solo da quante domande rispondi correttamente, ma anche dal numero di neuroni che usi per completare queste domande. Più attività svolgi con meno neuroni, più alto è il tuo QI.
Questa è esattamente l’idea centrale trasmessa dalla densità della conoscenza:
Ha due elementi. Un elemento è l'abilità di questo modello. Il secondo elemento è il numero di neuroni necessari per questa capacità, ovvero il corrispondente consumo di potenza di calcolo.
Rispetto ai 175 miliardi di parametri GPT-3 rilasciati da OpenAI nel 2020, nel 2024 ha rilasciato MiniCPM-2.4B con le stesse prestazioni ma solo 2,4 miliardi di parametri di GPT-3, che ha aumentato la densità di conoscenza di circa 86 volte.
Uno studio dell’Università di Toronto mostra anche che non tutti i dati sono necessari, identificando sottoinsiemi di alta qualità da grandi set di dati che sono più facili da elaborare e conservano tutte le informazioni e la diversità nel set di dati originale.
Anche se viene rimosso fino al 95% dei dati di addestramento, le prestazioni predittive del modello all'interno di una distribuzione specifica potrebbero non essere influenzate in modo significativo.

L'esempio più recente è il modello grande Meta Llama 3.1.
Quando Meta ha addestrato Llama 3, ha fornito dati di addestramento con token 15T, ma Thomas Scialom, un ricercatore di Meta AI responsabile del lavoro post-addestramento di Llama2 e Llama3, ha dichiarato: Il testo su Internet è pieno di informazioni inutili e allenamenti basati su queste informazioni rappresentano uno spreco di risorse informatiche.
"Non ci sono risposte scritte manualmente nell'addestramento successivo di Llama 3… utilizza solo dati puramente sintetici di Llama 2."
Inoltre, la distillazione della conoscenza è anche uno dei metodi importanti per "conquistare il grande con il piccolo".
La distillazione della conoscenza si riferisce all'utilizzo di un "modello insegnante" ampio e complesso per guidare la formazione di un "modello studente" piccolo e semplice, che può trasferire le potenti prestazioni e la capacità di generalizzazione superiore del modello grande a modelli più leggeri e computazionali Più piccoli che costano meno.

Dopo il rilascio di Llama 3.1, il CEO di Meta Zuckerberg ha scritto un lungo articolo "Open Source AI Is the Path Forward", in cui ha anche sottolineato l'importanza di mettere a punto e distillare piccoli modelli.
Dobbiamo addestrare, perfezionare e distillare i nostri modelli. Ogni organizzazione ha esigenze diverse che possono essere soddisfatte al meglio utilizzando modelli addestrati o perfezionati su scale diverse e con dati specifici.
Le attività sul dispositivo e le attività di classificazione richiedono modelli di piccole dimensioni, mentre le attività più complesse richiedono modelli di grandi dimensioni.
Ora puoi prendere modelli di lama all'avanguardia, continuare ad addestrarli sui tuoi dati e poi distillarli nella dimensione del modello che meglio si adatta alle tue esigenze, senza che noi o nessun altro veda i tuoi dati.
Nel settore si ritiene inoltre generalmente che le versioni 8B e 70B di Meta Llama 3.1 siano distillate da tazze ultra-grandi, pertanto le prestazioni complessive sono state notevolmente migliorate e anche l'efficienza del modello è maggiore.
Oppure, anche l’ottimizzazione dell’architettura del modello è fondamentale. Ad esempio, l’intenzione originale della progettazione di MobileNet è implementare modelli efficienti di deep learning sui dispositivi mobili.
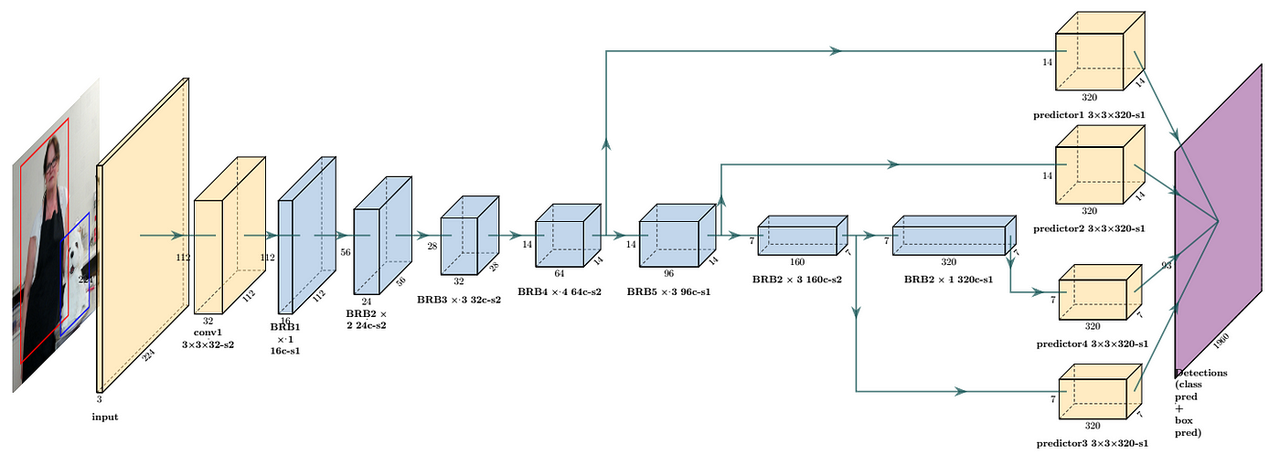
Riduce significativamente il numero di parametri del modello attraverso una convoluzione separabile in profondità. Rispetto a ResNet, MobileNetV1 riduce il numero di parametri di circa 8-9 volte.
MobileNet è computazionalmente più efficiente grazie al numero ridotto di parametri. Ciò è particolarmente importante per gli ambienti con risorse limitate, come i dispositivi mobili, poiché può ridurre significativamente i requisiti di elaborazione e archiviazione senza sacrificare troppo le prestazioni.
Nonostante i progressi compiuti a livello tecnico, l’industria dell’intelligenza artificiale stessa deve ancora affrontare la sfida degli investimenti a lungo termine e dei costi elevati, e il ciclo di ritorno è relativamente lungo.
Secondo le statistiche incomplete del "Daily Economic News", alla fine di aprile di quest'anno in Cina erano stati lanciati in totale circa 305 modelli di grandi dimensioni, ma al 16 maggio c'erano ancora circa 165 modelli di grandi dimensioni che non erano ancora stati lanciati. registrazione completata.
Il fondatore di Baidu, Robin Li, ha criticato pubblicamente che l'esistenza di molti modelli di base attuali è uno spreco di risorse e ha suggerito che le risorse dovrebbero essere utilizzate maggiormente per esplorare la possibilità di combinare modelli con industrie e per sviluppare la prossima potenziale super applicazione.

Anche questa è una questione centrale nell’attuale settore dell’intelligenza artificiale, la contraddizione sproporzionata tra l’aumento del numero di modelli e l’implementazione di applicazioni pratiche.
Di fronte a questa sfida, l’attenzione del settore si è gradualmente spostata verso l’accelerazione dell’applicazione della tecnologia AI, e i modelli piccoli con bassi costi di implementazione e maggiore efficienza sono diventati un punto di svolta più adatto.
Così abbiamo notato che cominciavano ad emergere alcuni piccoli modelli focalizzati su ambiti specifici, come modelli grandi per la cucina e modelli grandi per il live streaming. Anche se questi nomi possono sembrare un bluff, sono esattamente sulla strada giusta.
Insomma, l’AI del futuro non sarà più un’unica, enorme esistenza, ma sarà più diversificata e personalizzata. L'ascesa dei modelli piccoli riflette questa tendenza. Le loro eccellenti prestazioni in compiti specifici dimostrano che "piccolo ma bello" può anche conquistare rispetto e riconoscimento.
Un'altra cosa
Se desideri eseguire il modello in anticipo sul tuo iPhone, potresti anche provare un'app iOS chiamata "Hugging Chat" lanciata da Hugging Face.
L'app può essere scaricata con l'aiuto dell'account App Store del Magic Hemei District, quindi gli utenti possono accedere e utilizzare vari modelli open source, inclusi ma non limitati a Phi 3,
Mixtral, Command R+ e altri modelli.
Ricordo caldo: per una migliore esperienza e prestazioni, si consiglia di utilizzare la versione Pro di ultima generazione di iPhone.
Link per il download: https://apps.apple.com/us/app/huggingchat/id6476778843
# Benvenuto per seguire l'account pubblico WeChat ufficiale di Aifaner: Aifaner (ID WeChat: ifanr) Ti verranno forniti contenuti più interessanti il prima possibile.
Ai Faner |. Link originale · Visualizza commenti · Sina Weibo
