
Comprendi la terza puntata del progetto open source DeepSeek in un articolo, 300 righe di codice rivelano la chiave dietro l’efficienza di inferenza di V3/R1

Nel terzo giorno dell'Open Source Week, DeepSeek non solo ha portato tecnologia, ma ha anche diffuso la buona notizia che R2 è in arrivo. Come utente, vedere le librerie tecnologiche scartate da DeepSeek e vedere i modelli che applicano queste tecnologie non è un modo per assistere alla nascita di una superstar.
L'introduzione di oggi è DeepGEMM, una libreria progettata per la moltiplicazione generale di matrici (GEMM) FP8 pulita ed efficiente, con funzionalità di ridimensionamento a grana fine, come descritto in DeepSeek-V3. Supporta GEMM raggruppati di esperti normali e misti (MoE). La libreria è scritta in CUDA e non richiede compilazione durante l'installazione, utilizza invece moduli JIT (leggeri) per compilare tutti i kernel in fase di runtime.
Non intendo dire che DeepSeek non sia potente, ma negli ultimi tre giorni si è visto dagli open source che, anche se sono supportati da Magic Square, non sono ricchi di risorse come le grandi aziende e devono lavorare duro per spremere le risorse informatiche.
Anche questa volta GeepGEMM non abbandona questo tema Rispetto alle tecnologie precedenti, i vantaggi di DeepGEMM sono:
- Maggiore efficienza: riduzione del sovraccarico computazionale e di memoria grazie all'8° PQ e all'accumulo a due livelli
- Distribuzione flessibile: la compilazione JIT è altamente adattabile e riduce gli oneri di precompilazione
- Ottimizzazione mirata: supporta MoE e si adatta profondamente al core tensore Hopper
- Design più semplice: meno codice di base, evita dipendenze complesse ed è facile da apprendere e ottimizzare
Queste caratteristiche lo distinguono nel moderno computing AI, soprattutto negli scenari che richiedono inferenza efficiente e basso consumo energetico .
Progettato per l'informatica moderna basata sull'intelligenza artificiale
Maggiore efficienza e implementazione più flessibile sono i punti salienti di DeepGEMM. La logica di base è composta da solo circa 300 righe di codice, ma supera il kernel ottimizzato a livello di esperti nella maggior parte delle dimensioni della matrice. Fino a 1350+ FP8 TFLOPS su GPU Hopper.
FP8 è un metodo di compressione dei numeri, che equivale a ridurre i numeri che originariamente richiedono archiviazione a 32 o 16 bit in archiviazione a 8 bit. Proprio come prendi appunti con foglietti adesivi più piccoli, anche se puoi scrivere meno contenuti su ogni pezzo di carta, è più veloce da trasportare e trasferire .
Il vantaggio di questo calcolo compresso è che occupa meno memoria: un'attività della stessa dimensione richiede meno "note adesive" e lo spostamento di piccoli pezzi di carta è più veloce di file di grandi dimensioni, quindi anche la velocità di calcolo è più veloce. Ma la sfida è che è facile commettere errori.
Per risolvere il problema della precisione dell'FP8, DeepGEMM utilizza un intelligente "metodo in due fasi": utilizzare l'FP8 per eseguire moltiplicazioni su larga scala, come utilizzare una calcolatrice per premere rapidamente una serie di risultati. In questa fase gli errori sono inevitabili.
Ma non importa, c’è un secondo passaggio: l’aggregazione ad alta precisione. Di tanto in tanto, questi risultati vengono convertiti in una somma più accurata di 32 cifre e la somma viene attentamente controllata con un foglio di carta per evitare l'accumulo di errori.
Esegui prima, quindi passa attraverso due livelli di correzione degli errori cumulativi. Attraverso questo design, DeepGEMM consente ai modelli di intelligenza artificiale di funzionare in modo più fluido su telefoni cellulari, computer e altri dispositivi riducendo al contempo il consumo energetico, rendendolo adatto a scenari applicativi più complessi in futuro .

Includendo l'applicazione della compilazione JIT, l'idea è simile. Compilazione JIT, il nome completo è compilazione "Just-In-Time". In cinese, può essere chiamata compilazione just-in-time e il concetto corrispondente è compilazione statica.
Un programma generale deve essere scritto e compilato prima di essere utilizzato e trasformato in un linguaggio comprensibile al computer. Ma la compilazione JIT è diversa: trasforma il codice solo in istruzioni che il computer può eseguire quando il programma è in esecuzione.
Può regolare il codice sul posto in base alle condizioni del tuo computer (come la scheda grafica NVIDIA Hopper) e personalizzare le istruzioni più adatte. Non è rigido come la precompilazione, in modo che il programma possa funzionare in modo più fluido. Compila solo le parti che ti servono al momento, senza sprecare tempo e spazio, e fai in modo che tutto sia perfetto.
Il tensor core di Hopper e la compilazione JIT sono i migliori partner. La compilazione JIT può generare codice ottimale in loco in base alla scheda grafica Hopper in fase di runtime, massimizzando l'efficienza di calcolo del tensor core.
DeepGEMM supporta GEMM ordinari e GEMM raggruppati di esperti misti (MoE), che hanno requisiti computazionali diversi. La compilazione JIT può adattare temporaneamente il codice in base alle caratteristiche dell'attività e mobilitare direttamente la funzione del motore di calcolo o trasformazione FP8 del tensor core per ridurre gli sprechi e aumentare la velocità.
Come descrivere una via così tecnica: sottile, leggera e affilata .
Per la maggior parte degli sviluppatori, DeepGEMM può essere considerata un'altra buona notizia. Di seguito sono riportate le informazioni relative alla distribuzione, potresti voler giocarci.
Guida alla distribuzione di DeepGEMM
DeepGEMM è una libreria ottimizzata per la moltiplicazione generale di matrici (GEMM) dell'FP8 con un meccanismo di ridimensionamento raffinato e proposta in DeepSeek-V3. Supporta GEMM standard e GEMM raggruppati Mixed Expert (MoE). La libreria è scritta in CUDA e non necessita di essere precompilata durante l'installazione. Tutte le funzioni principali vengono invece compilate in fase di esecuzione tramite un leggero modulo di compilazione just-in-time (JIT).
Attualmente, DeepGEMM supporta solo i tensor core NVIDIA Hopper. Per risolvere il problema dell'insufficiente precisione di calcolo del tensor core FP8, utilizza la tecnologia di accumulo (boost) a due livelli del core CUDA per l'ottimizzazione. Sebbene prenda in prestito alcuni concetti da CUTLASS e CuTe, DeepGEMM non si affida troppo ai loro modelli o alle operazioni matematiche, punta invece alla semplicità e contiene solo una funzione di calcolo principale del kernel con circa 300 righe di codice. Ciò rende DeepGEMM una risorsa di riferimento chiara e di facile comprensione per l'apprendimento delle tecniche di moltiplicazione e ottimizzazione delle matrici di Hopper FP8.
Nonostante il suo design semplice, le prestazioni di DeepGEMM su una varietà di forme di matrice sono paragonabili, e in alcuni casi addirittura migliori, a quelle delle librerie ottimizzate professionalmente.
prestazione
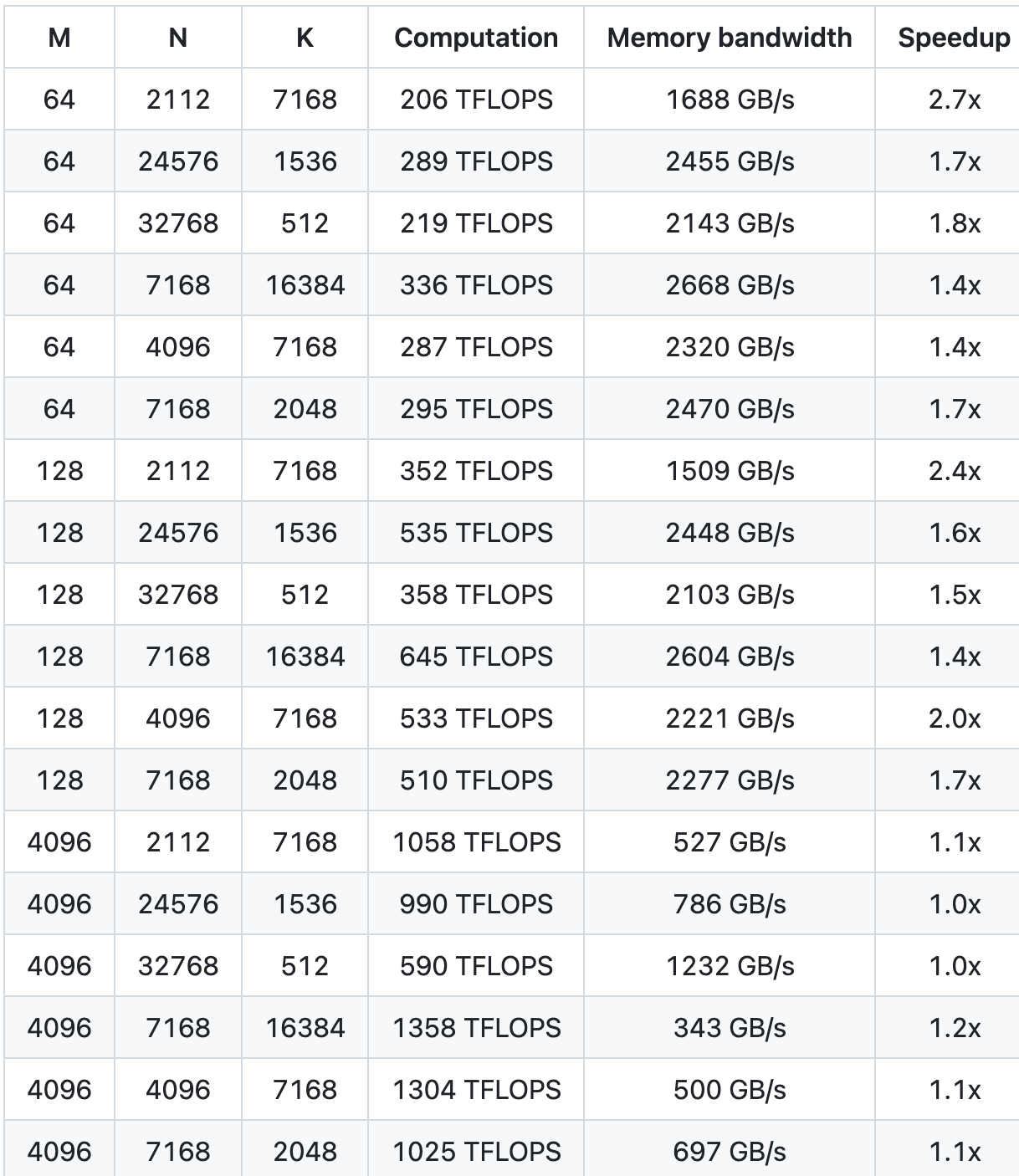
Abbiamo testato utilizzando NVCC 12.8 su H800, coprendo tutte le forme di matrice che possono essere utilizzate durante l'inferenza DeepSeek-V3/R1 (inclusi pre-riempimento e decodifica, ma senza coinvolgere il parallelismo del tensore). Tutti i parametri di accelerazione sono calcolati in base alla nostra implementazione CUTLASS 3.6 attentamente ottimizzata internamente.
Le prestazioni di DeepGEMM sotto alcune forme di matrice specifiche non sono ideali. Se sei interessato all'ottimizzazione, puoi inviare PR relativi all'ottimizzazione.
GEMM standard per modelli densi
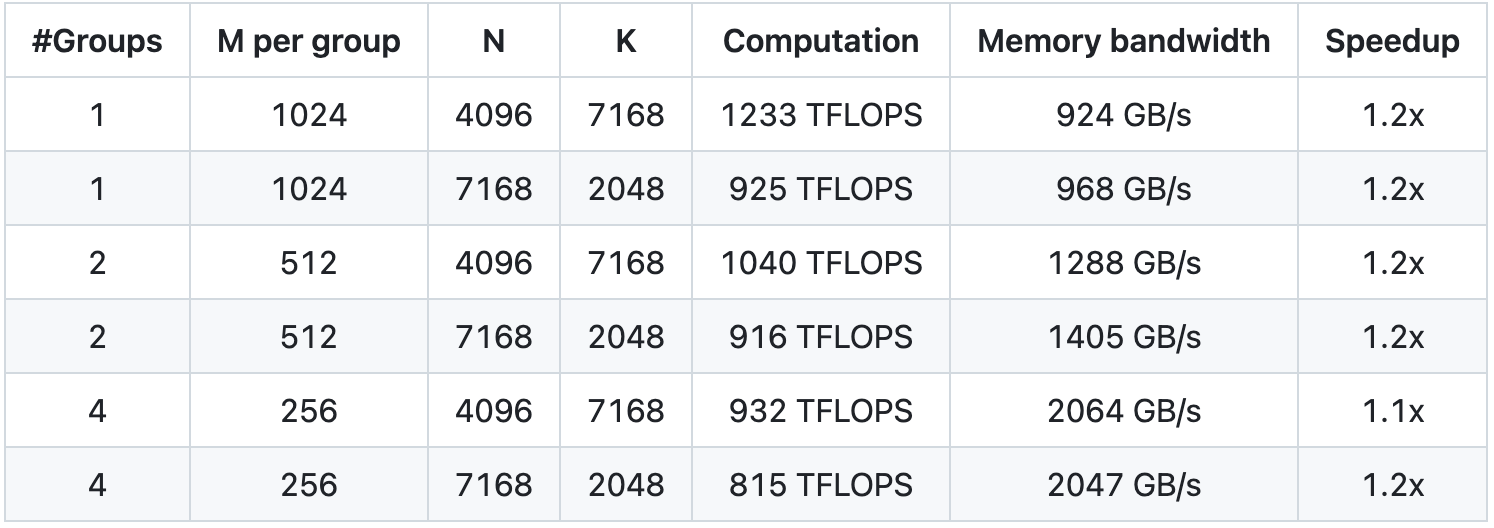
GEMM raggruppato per il modello MoE (layout continuo)
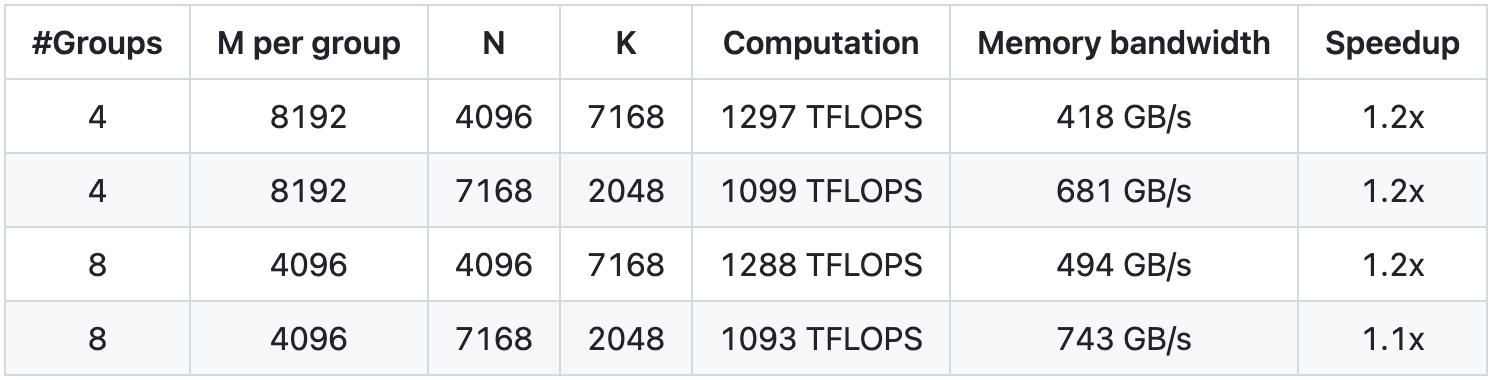
GEMM raggruppato (layout maschera) per il modello MoE
inizio veloce
Requisiti ambientali
- La GPU con architettura Hopper deve supportare sm_90a
- Python 3.8 e versioni successive
- CUDA versione 12.3 e successive (la versione 12.8 e successive è altamente consigliata per ottenere le migliori prestazioni)
- PyTorch 2.1 e versioni successive
- CUTLASS 3.6 e versioni successive (può essere clonato tramite il sottomodulo Git)
sviluppare
# Il sottomodulo deve essere clonato
git clone –recursive [email protected]:deepseek-ai/DeepGEMM.git# Crea collegamenti simbolici per directory di terze parti (CUTLASS e CuTe).
sviluppo di python setup.py# Testare la compilazione JIT
python test/test_jit.py# Testare tutti gli strumenti GEMM (normali, raggruppati contigui e raggruppati mascherati)
python test/test_core.py
Installare
installazione di python setup.py
Quindi importa deep_gemm nel tuo progetto Python e divertiti ad usarlo!
In allegato è riportato l'indirizzo open source di GitHub:
https://github.com/deepseek-ai/DeepGEMM
Autore: Liu Ya, Mo Chongyu
# Benvenuto per seguire l'account pubblico WeChat ufficiale di Aifaner: Aifaner (ID WeChat: ifanr) Ti verranno forniti contenuti più interessanti il prima possibile.
Ai Faner |. Link originale · Visualizza commenti · Sina Weibo