
Come trovare e rimuovere file duplicati su Linux usando fdupes
Quando si lavora con grandi quantità di supporti e documenti, è abbastanza comune accumulare più copie dello stesso file sul computer. Inevitabilmente, ciò che segue è uno spazio di archiviazione disordinato pieno di file ridondanti, che provoca controlli periodici per file duplicati sul tuo sistema.
A tal fine, troverai vari programmi per identificare ed eliminare i file duplicati. E fdupes sembra essere uno di questi programmi per Linux. Quindi segui mentre discutiamo di fdupes e ti guidiamo attraverso i passaggi per trovare ed eliminare i file duplicati su Linux.
Che cos’è fdupes?
Fdupes è un programma basato su CLI per trovare ed eliminare file duplicati su Linux. È rilasciato sotto la licenza MIT su GitHub .
Nella sua forma più semplice, il programma funziona eseguendo la directory specificata tramite md5sum per confrontare le firme MD5 dei suoi file. Quindi esegue un confronto byte per byte su di essi per identificare i file duplicati e garantire che non vengano esclusi i duplicati.
Una volta che fdupes identifica i file duplicati, ti dà la possibilità di eliminarli o sostituirli con collegamenti reali (collegamenti ai file originali). Quindi, a seconda delle tue esigenze, puoi procedere con un’operazione di conseguenza.
Come installare fdupes su Linux?
Fdupes è disponibile sulla maggior parte delle principali distribuzioni Linux come Ubuntu, Arch, Fedora, ecc. In base alla distribuzione che stai eseguendo sul tuo computer, impartisci i comandi indicati di seguito.
Su sistemi basati su Ubuntu o Debian:
sudo apt install fdupesPer installare fdupes su Fedora/CentOS e altre distribuzioni basate su RHEL:
sudo dnf install fdupesSu Arch Linux e Manjaro:
sudo pacman -S fdupesCome usare fdupes?
Dopo aver installato il programma sul tuo computer, segui i passaggi seguenti per trovare e rimuovere i file duplicati.
Trovare file duplicati con fdupes
Innanzitutto, iniziamo cercando tutti i file duplicati in una directory. La sintassi di base per questo è:
fdupes path/to/directoryAd esempio, se desideri trovare file duplicati nella directory Documenti , esegui:
fdupes ~/DocumentsProduzione:
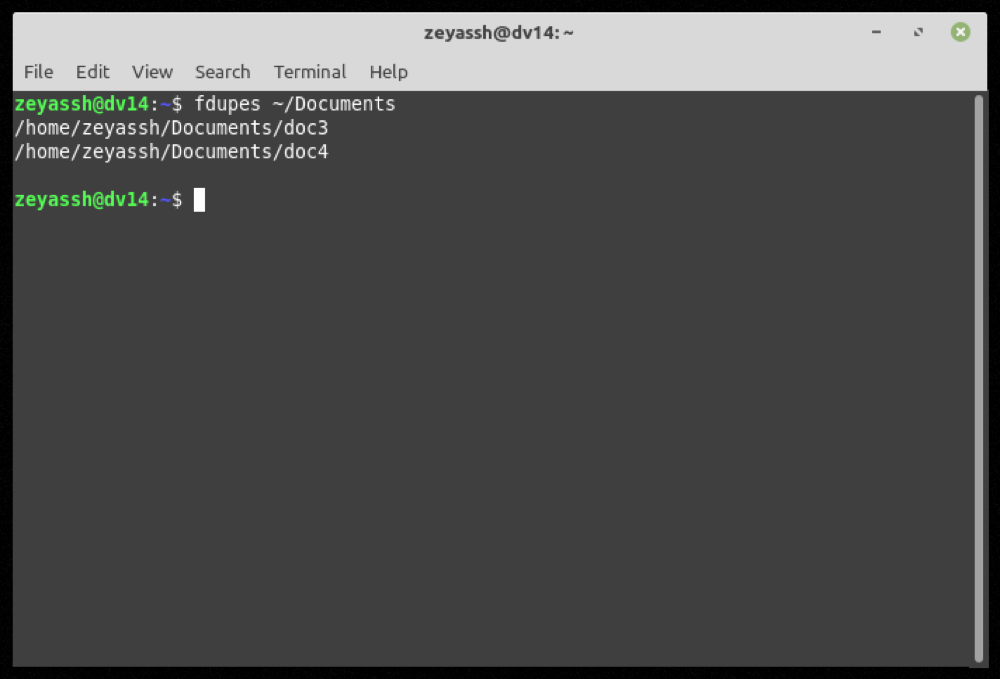
Se fdupes trova file duplicati nella directory specificata, restituirà un elenco di tutti i file ridondanti raggruppati per set, e potrai quindi eseguire ulteriori operazioni su di essi, se necessario.
Tuttavia, se la directory che hai specificato è costituita da sottodirectory, il comando precedente non identificherà i duplicati al loro interno. In tali situazioni, quello che devi fare è effettuare una ricerca ricorsiva per trovare tutti i file duplicati presenti all’interno delle sottodirectory.
Per eseguire una ricerca ricorsiva in fdupes, usa il flag -r :
fdupes -r path/to/directoryPer esempio:
fdupes -r ~/DocumentsProduzione:
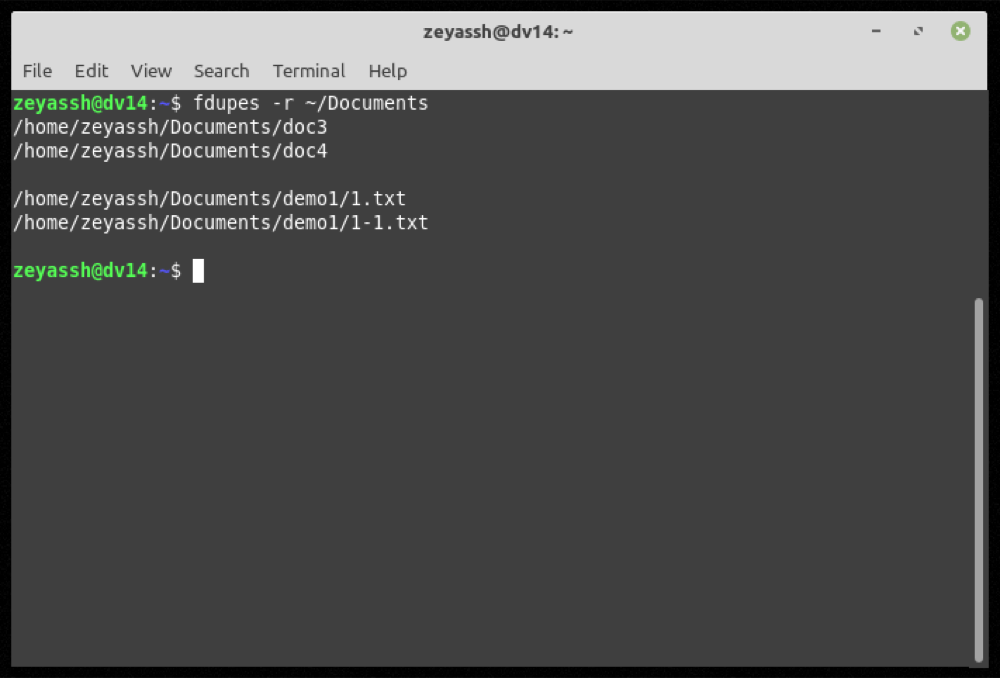
Sebbene i due comandi precedenti possano facilmente trovare file duplicati all’interno della directory specificata (e delle sue sottodirectory), il loro output include anche file duplicati di lunghezza zero (o vuoti).
Sebbene questa funzionalità possa ancora tornare utile quando hai troppi file duplicati vuoti sul tuo sistema, può creare confusione quando vuoi solo scoprire duplicati non vuoti in una directory.
Fortunatamente, fdupes ti permette di escludere i file di lunghezza zero dai suoi risultati di ricerca usando l’opzione -n , che puoi usare nei tuoi comandi.
Nota: è possibile escludere file duplicati non vuoti sia nelle ricerche normali che in quelle ricorsive.
Per cercare solo file duplicati non vuoti sul tuo computer:
fdupes -n ~/DocumentsProduzione:
Se hai a che fare con più set di file duplicati, è consigliabile inviare i risultati in un file di testo per riferimento futuro.
Per fare ciò, esegui:
fdupes path/to/directory > file_name.txt…dove path/to/directory è la directory in cui si desidera eseguire la ricerca.
Per cercare file duplicati nella directory Documenti e quindi inviare l’output a un file:
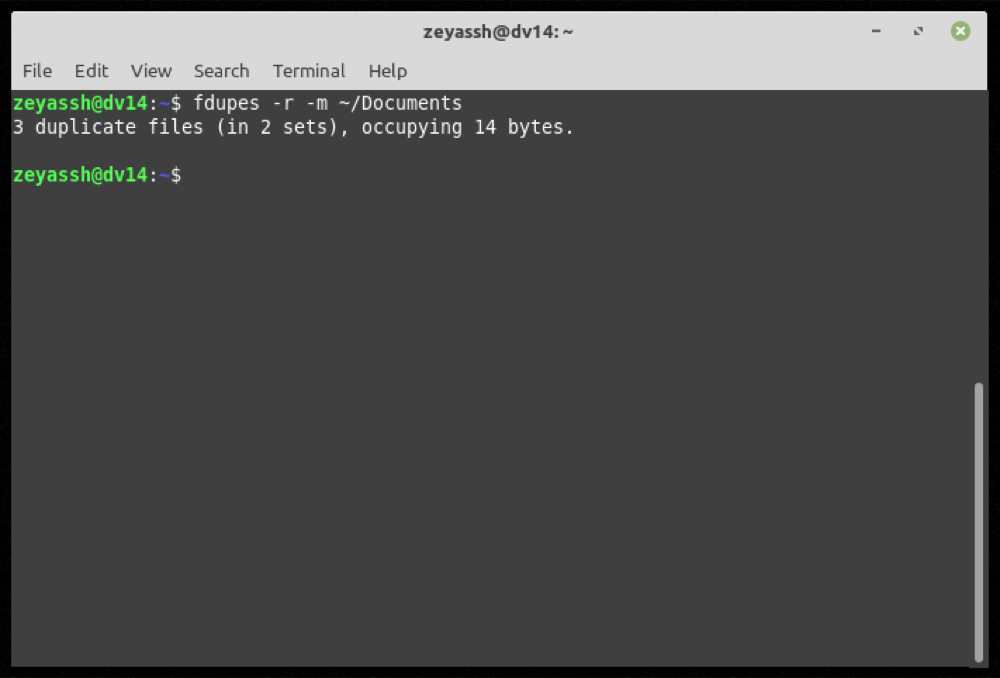
fdupes /home/Documents > output.txtUltimo ma non meno importante, se desideri vedere un riepilogo di tutte le informazioni relative ai file duplicati in una directory, puoi utilizzare il flag -m nei tuoi comandi:
fdupes -m path/to/directoryPer ottenere informazioni sui file duplicati per la directory Documenti :
fdupes -m ~/DocumentsProduzione:
In qualsiasi momento durante l’utilizzo di fdupes, se si desidera assistenza con un comando o una funzione, utilizzare l’opzione -h per ottenere l’aiuto dalla riga di comando :
fdupes -h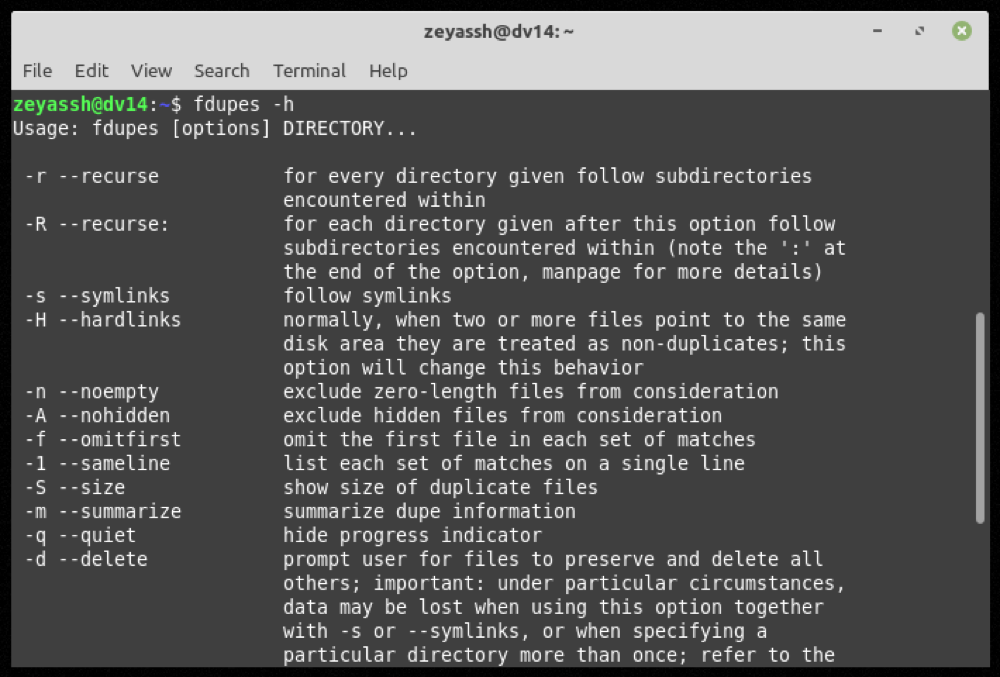
Eliminazione di file duplicati in Linux con fdupes
Dopo aver identificato i file duplicati in una directory, puoi procedere con la rimozione/eliminazione di questi file dal sistema per eliminare il disordine e liberare spazio di archiviazione.
Per eliminare un file duplicato, specifica il flag -d con il comando e premi Invio :
fdupes -d path/to/directoryPer rimuovere i file duplicati nella cartella Download :
fdupes -d ~/DownloadsFdupes ti presenterà ora un elenco di tutti i file duplicati in quella directory e ti darà la possibilità di conservare quelli che vuoi conservare sul tuo computer.
Ad esempio, se vuoi preservare il primo file nel set 1, inserisci 1 dopo l’output di una ricerca fdupes e premi Invio .
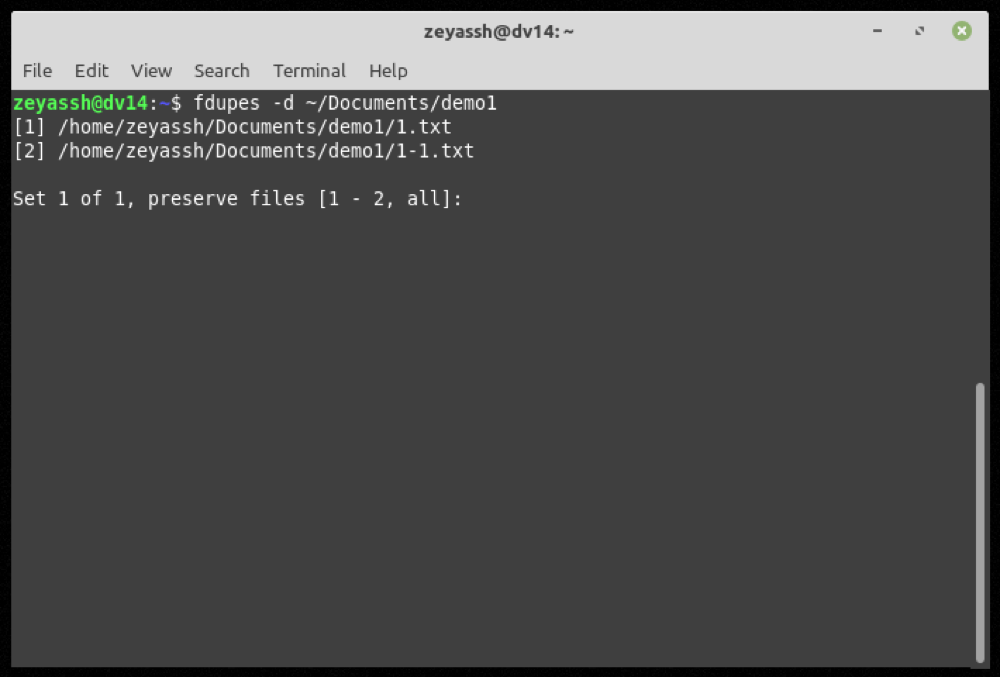
Inoltre, se necessario, è anche possibile salvare più istanze di file in una serie di file duplicati restituiti. Per questo, è necessario inserire i numeri corrispondenti ai file duplicati in un elenco separato da virgole e premere Invio .
Ad esempio, se vuoi salvare i file 1, 3 e 5, devi inserire:
1,3,5Nel caso in cui desideri preservare la prima istanza di un file in ogni set di file duplicati e desideri ignorare il prompt, puoi farlo includendo l’ opzione -N , come mostrato nel seguente comando:
fdupes -d -N path/to/directoryPer esempio:
fdupes -d -N ~/DocumentsEliminazione riuscita di file duplicati in Linux
L’organizzazione dei file è un compito noioso in sé e per sé. Aggiungeteci i problemi che causano i file duplicati, e avrete a disposizione poche ore di tempo e fatica sprecati nell’organizzazione del vostro spazio di archiviazione disordinato.
Ma grazie a utility come fdupes, è molto più semplice ed efficiente identificare i file duplicati ed eliminarli. E la guida sopra dovrebbe aiutarti con queste operazioni sulla tua macchina Linux.
Proprio come i file duplicati, anche le parole duplicate e le righe ripetute in un file possono essere frustranti da gestire e richiedono la rimozione di strumenti avanzati. Se affronti anche questi problemi, puoi utilizzare uniq per rimuovere le righe duplicate da un file di testo.
